在项目中使用redis做缓存的一些思路
目录
在项目中redis做缓存的一些思路
首先,缓存的对象有三种
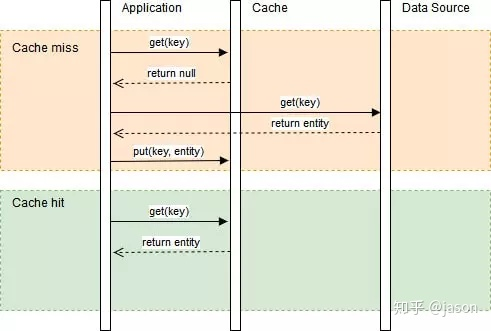
1、数据库中单条的的数据(以表名跟id作为key永久保存到redis),在有更新的地方都要更新缓存(不适用于需要经常更新的数据);
2、对于一些不分页,不需要实时(需要多表查询)的列表,我们可以将列表结果缓存到redis中,设定一定缓存时间作为该数据的存活时间。用获取该列表的方法名作为key,列表结果为value;这种情况只试用于不经常更新且不需要实时的情况下。
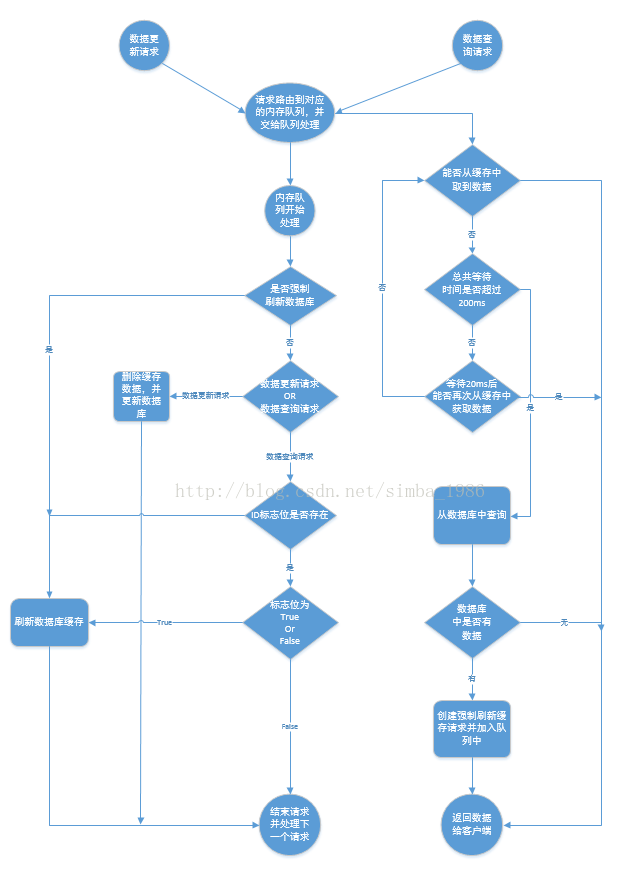
3、不需要实时的,需要分页的列表:可以把分页的结果列表放到一个map(key为分页标识,value为分页结果)中,然后将该map存到redis的list中(用该方法名为key)。然后给该list设置一个缓存存活时间(用expire)。这样通过方法名lrange出来就能获取存有分页列表的数据,遍历该list,通过遍历list中map的key判断该分页数据是否在缓存内,是则返回,不存在则rpush进去。这种做法能解决比如1-5页的数据已经重新加载,而6-10页的数据依然是缓存的数据而导致脏数据的情况。
本人走过的一些弯路
1、对于数据缓存不是所有东西都缓存到redis就是好的,而是要针对一些改动不大或者访问率大的数据进行缓存来减少关系型数据库的压力。
2、不要试图在拦截器或者过滤器中判断是否有缓存的存在,因为每个请求(不管该请求对应的方法是否做了缓存)它都会去redis中请求数据并判断,这样会浪费一定的内存资源跟响应时间。所以应该针对需要缓存的方法进行判断。
3、一个方法中使用多个get或者set的方法,我们需要尽可能的减少去jedispool中获取jedis对象,所以在一个方法中应该只获取一次jedis对象,在方法结束的时候把该对象return还给连接池,这样才能做到尽可能的高效。
4、在设置连接池中参数的时候要考虑到自身系统需求,不然会经常出现连接池中无可用对象获取,spring时不时发起连接请求到redis等不必要的错误和资源浪费。
为什么没用Redis做缓存
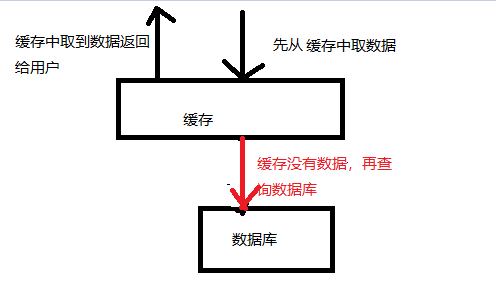
都知道用Redis作缓存非常的快,但事实上有些时候我们并没有使用Redis来做缓存,而是采用本地缓存的方式。就比如我所接触的一个项目,就没有采用Redis作缓存,而是使用谷歌工具包中的Table来作的缓存。
这个Table其实就是一个数据结构,你可以把它当做Map来看待。现在我们来画两幅图,分别是使用Table做缓存和使用Redid做缓存的两种情况
使用Table作本地缓存

使用Redis作缓存

公司采用本地缓存的方式,那么为什么没有采用Redis呢
让我们来思考一下下面几个问题
1、访问本地服务缓存快还是远程服务Redis快?
毫无疑问是访问本地服务的缓存要更快一些,Redis毕竟是在远程服务上。假设我们访问本地服务缓存的延迟为50ms,那么访问远程Redis的验证可能会达到58ms。这是使用本地缓存服务的优势所在
2、Reids事务
在Redis中,虽然Redis的操作都能够保证原子性,但是Redis中的事务不能够保证原子性。比如说A用户想B用户转账,怎么保证它的事务呢
3、Redis会多一次IO
尽管Redis数据存放在内存上,但Redis持久化操作还是会将数据写在磁盘上,IO操作会增加耗时。而本地缓存使用的只是一个数据结构来存储数据,不存在IO
那么使用本地缓存的问题是什么呢?
比如说A用户的数据存放在exchange1节点上,而B用户的数据存放在exchange2节点上。现在A用户想向B用户转账,那么就会比较麻烦,要做一些其他的操作,这是使用本地缓存的一个很大的弊端
什么时候使用Redis?
由于公司的项目是一个证券交易所,对延迟的要求比较高,想尽可能的做到低延迟,所以最终舍弃使用Redis。对于一些不太注重延迟的项目,使用Redis做缓存是非常不错的
以上为个人经验,希望能给大家一个参考,也希望大家多多支持潘少俊衡。
版权声明
本文仅代表作者观点,不代表本站立场。
本文系作者授权发表,未经许可,不得转载。
本文地址:/shujuku/Redis/102436.html