redis缓存穿透解决方法
缓存技术可以用来减轻数据库的压力,提升访问效率。目前在企业项目中对缓存也是越来越重视。但是缓存不是说随随便便加入项目就可以了。将缓存整合到项目中,这才是第一步。而缓存带来的穿透问题,进而导致的雪蹦问题都是我们迫切需要解决的问题。本篇文章将我平时项目中的解决方案分享给大家,以供参考。
一、缓存穿透的原理
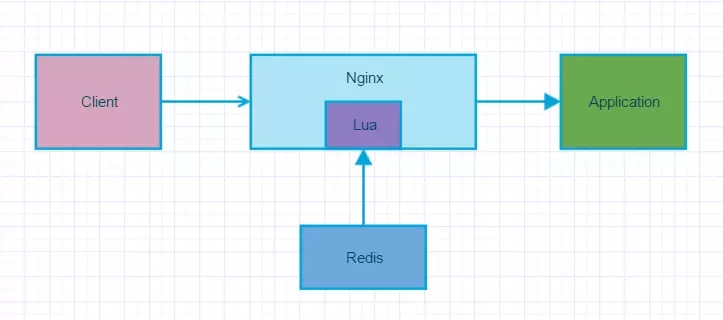
缓存的正常使用如图:

如图所示,缓存的使用流程:
1、先从缓存中取数据,如果能取到,则直接返回数据给用户。这样不用访问数据库,减轻数据库的压力。
2、如果缓存中没有数据,就会访问数据库。
这里面就会存在一个BUG,如图:

如图,缓存就像是数据库的一道防火墙,将请求比较频繁的数据放到缓存中,从而减轻数据库的压力。 但是如果有人恶意攻击,那就很轻松的穿透你的缓存,将所有的压力都给数据库。比如上图,你缓存的key都是正整数,但是我偏偏使用负数作为key访问你的缓存,这样就会导致穿透缓存,将压力直接给数据库。
二、导致缓存穿透的原因
缓存穿透的问题,肯定是再大并发情况下。依此为前提,我们分析缓存穿透的原因如下:
1、恶意攻击,猜测你的key命名方式,然后估计使用一个你缓存中不会有的key进行访问。
2、第一次数据访问,这时缓存中还没有数据,则并发场景下,所有的请求都会压到数据库。
3、数据库的数据也是空,这样即使访问了数据库,也是获取不到数据,那么缓存中肯定也没有对应的数据。这样也会导致穿透。
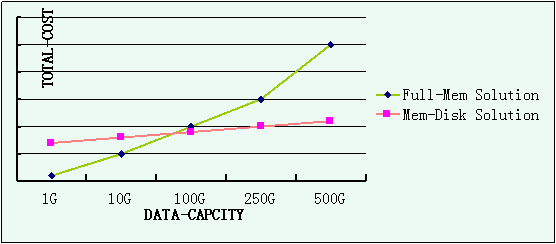
三、解决缓存穿透
缓存穿透在于一步步规避穿透的原因,如图:

如上图所示,解决的步骤如下:
1、再web服务器启动时,提前将有可能被频繁并发访问的数据写入缓存。—这样就规避大量的请求在第3步出现排队阻塞。
2、规范key的命名,并且统一缓存查询和写入的入口。这样,在入口处,对key的规范进行检测。–这样保存恶意的key被拦截。
3、Synchronized双重检测机制,这时我们就需要使用同步(Synchronized)机制,在同步代码块前查询一下缓存是否存在对应的key,然后同步代码块里面再次查询缓存里是否有要查询的key。 这样“双重检测”的目的,还是避免并发场景下导致的没有意义的数据库的访问(也是一种严格避免穿透的方案)。
这一步会导致排队,但是第一步中我们说过,为了避免大量的排队,可以提前将可以预知的大量请求提前写入缓存。
4、不管数据库中是否有数据,都在缓存中保存对应的key,值为空就行。–这样是为了避免数据库中没有这个数据,导致的平凡穿透缓存对数据库进行访问。
5、第4步中的空值如果太多,也会导致内存耗尽。导致不必要的内存消耗。这样就要定期的清理空值的key。避免内存被恶意占满。导致正常的功能不能缓存数据。
版权声明
本文仅代表作者观点,不代表本站立场。
本文系作者授权发表,未经许可,不得转载。
本文地址:/shujuku/Redis/103191.html