百度蜘蛛日志抓取解读 提高百度收录
很多网站目前使用的都是虚拟空间,都能够提供日志。日志是指在网站根目录下的logfiles文件夹里面日期.txt文本文件有很多介绍通过http查看返回命令的那种办法来查看蜘蛛。现在更多的网站是没有提供可以通过软件来查看的日志格式。
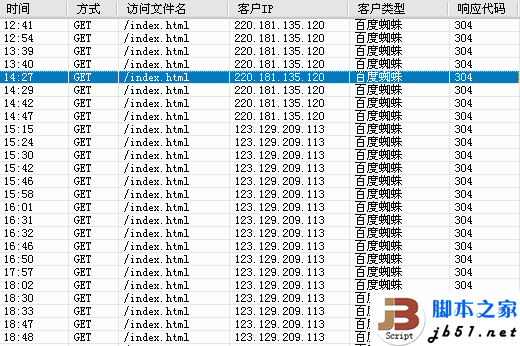
更多的是类似下面的日志格式,如下:
03:28:34 GET /goods.php 202.108.7.205 200 34696 390
第一 03:28:34 访问时间
第二 GET /goods.php 访问的页面 get表示获取
第三 202.108.7.205 访问网站的源IP
第四 200 成功访问
第五 34696 390 表示记录的内容大小
接下来要介绍几个HTTP状态码扩展基本知识:
成功2×× 成功处理了请求的状态码。
200 服务器已成功处理了请求并提供了请求的网页。
204 服务器成功处理了请求,但没有返回任何内容。
重定向3××每次请求中使用重定向不要超过 5 次。
301 请求的网页已永久移动到新位置。当URLs发生变化时,使用301代码。搜索引擎索引中保存新的URL。
302 请求的网页临时移动到新位置。搜索引擎索引中保存原来的URL。
304 如果网页自请求者上次请求后没有更新,则用304代码告诉搜索引擎机器人,可节省带宽和开销。
客户端错误4×× 表示请求可能出错,妨碍了服务器的处理。
400 服务器不理解请求的语法。
403 服务器拒绝请求。
404 服务器找不到请求的网页。服务器上不存在的网页经常会返回此代码。
服务器错误5××表示服务器在处理请求时发生内部错误。这些错误可能是服务器本身的错误,而不是请求出错。
500 服务器遇到错误,无法完成请求。
503 服务器目前无法使用(由于超载或停机维护)。通常,这只是暂时状态。
以上日志提取于:http://www..027zhan.com 如果你不会提取日志的话
查看服务器日志办法:日志默认存放在System32\LogFiles目录下,使用W3C扩展格式
虚拟主机查看日志办法:根目录下logfiles文件(一般需虚拟主机面板中开启日志记录)
2010-05-06 17:48:16 W3SVC945321 222.73.167.138 GET /FUKE/CARNATION.html - 80 - 123.125.66.42 Baiduspider+(+http://www.baidu.com/search/spider.htm) 200 0 0 7341
1、2010-05-06 17:48:16 蜘蛛光临的时间
2、W3SVC945321 日志文件名
3、222.73.167.138 网站服务器IP地址
4、GET 是从服务器上获取数据
5、/FUKE/CARNATION.html 抓取的文件
6、- 80 - 80端口
7、123.125.66.42 蜘蛛的来路地址
8、Baiduspider+ 百度蜘蛛的名字
9、+http://www.baidu.com/search/spider.htm 百度蜘蛛机器人的介绍
10、200 0 0 7341 200服务器成功返回网页
版权声明
本文仅代表作者观点,不代表本站立场。
本文系作者授权发表,未经许可,不得转载。
本文地址:/yunying/SEO/122063.html