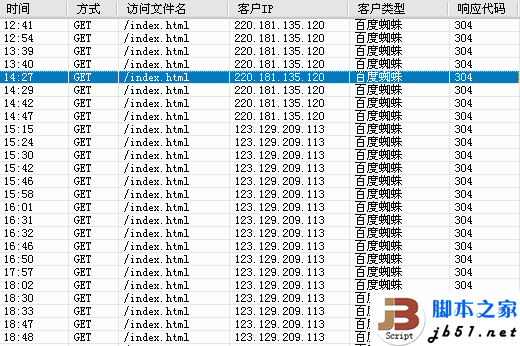
简单的分析一下百度蜘蛛的日常工作习性
搜索引擎用来爬行和访问页面的程序被称为蜘蛛工,也称为机器人(bot)。搜索引擎蜘蛛访问网站页面时类似于普通用户使用的浏览器。蜘蛛程序发出页面访问请求后,服务器返回HTML代码,蜘蛛程序把收到的代 码存入原始页面数据库。搜索引擎为了提高爬行和抓取速度,都使用多个蜘蛛并发分布爬行。
一、robots.txt文件
蜘蛛访问任何一个网站时,都会先访问网站根目录下的robots.txt文件。如果robots.txt文件禁止搜素引擎抓取某些文件或目录。蜘蛛将 遵守协议,不抓取被禁止的网址。
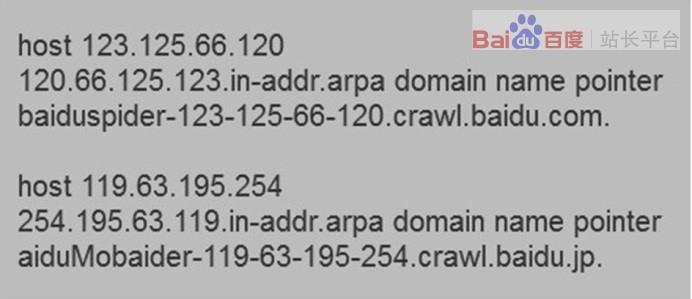
和浏览器一样,搜索引擎蜘蛛也有标明自己身份的代理名称,站长可以在日志文件中看到搜索引擎的特定代理名称,从而辨识搜索引擎蜘 蛛。下面列出常见的搜索引攀蜘蛛名称:
二、跟踪链接
为了抓取网上尽量多的页面,搜索引擎蜘蛛会跟踪页面上的链接,从一个页面爬到下一个页面,就好像蜘蛛在蜘蛛网上爬行那样,这也就 是搜索引擎蜘蛛这个名称的由来。
整个互联网是由相互链接的网站及页面组成的。从理论上说,蜘蛛从任何一个页面出发,顺着链接都可以爬行到网上的所有页面。当然, 由于网站及页面链接结构异常复杂,蜘蛛需要采取一定的爬行策略才能遍历网上所有页面。
最简单的爬行遍历策略分为两种,一种是深度优先,另一种是广度优先。
所谓深度优先,指的是蜘蛛沿着发现的链接一直向前爬行,直到前面再也没有其他链接,然后返回到第一个页面,沿着另一个链接再一直 往前爬行。
蜘蛛跟踪链接,从A页面爬行到Al,A2,A3,A4,到A4页面后,己经没有其他链接可以跟踪就返回A页面,顺着页面上的另一个链接,爬行 到B1,B2,B3,B4。在深度优先策略中,蜘蛛一直爬到无法再向前,才返回爬另一条线。
广度优先是指蜘蛛在一个页面上发现多个链接时,不是顺着一个链接一直向前,而是把页面上所有第一层链接都爬一遍,然后再沿着第二 层页面上发现的链接爬向第三层页面。比如,我的一个站点,股票入门大家可以去看下,研究下。
还有就是蜘蛛从A页面顺着链接爬行到Al,B1,C1页面,直到A页面上的所有链接都爬行完,然后再从A1页面发现的下一层链接,爬行到A2 ,A3,A4,从理论上说,无论是深度优先还是广度优先,只要给蜘蛛足够的时间,都能爬完整个互联网。在实际工作中,蜘蛛的带宽资源 ,时间都不是无限的。也不可能爬完所有页面。实际上最大的搜索引擎也只是爬行和收录了互联网的一小部分。
一、robots.txt文件
蜘蛛访问任何一个网站时,都会先访问网站根目录下的robots.txt文件。如果robots.txt文件禁止搜素引擎抓取某些文件或目录。蜘蛛将 遵守协议,不抓取被禁止的网址。
和浏览器一样,搜索引擎蜘蛛也有标明自己身份的代理名称,站长可以在日志文件中看到搜索引擎的特定代理名称,从而辨识搜索引擎蜘 蛛。下面列出常见的搜索引攀蜘蛛名称:
二、跟踪链接
为了抓取网上尽量多的页面,搜索引擎蜘蛛会跟踪页面上的链接,从一个页面爬到下一个页面,就好像蜘蛛在蜘蛛网上爬行那样,这也就 是搜索引擎蜘蛛这个名称的由来。
整个互联网是由相互链接的网站及页面组成的。从理论上说,蜘蛛从任何一个页面出发,顺着链接都可以爬行到网上的所有页面。当然, 由于网站及页面链接结构异常复杂,蜘蛛需要采取一定的爬行策略才能遍历网上所有页面。
最简单的爬行遍历策略分为两种,一种是深度优先,另一种是广度优先。
所谓深度优先,指的是蜘蛛沿着发现的链接一直向前爬行,直到前面再也没有其他链接,然后返回到第一个页面,沿着另一个链接再一直 往前爬行。
蜘蛛跟踪链接,从A页面爬行到Al,A2,A3,A4,到A4页面后,己经没有其他链接可以跟踪就返回A页面,顺着页面上的另一个链接,爬行 到B1,B2,B3,B4。在深度优先策略中,蜘蛛一直爬到无法再向前,才返回爬另一条线。
广度优先是指蜘蛛在一个页面上发现多个链接时,不是顺着一个链接一直向前,而是把页面上所有第一层链接都爬一遍,然后再沿着第二 层页面上发现的链接爬向第三层页面。比如,我的一个站点,股票入门大家可以去看下,研究下。
还有就是蜘蛛从A页面顺着链接爬行到Al,B1,C1页面,直到A页面上的所有链接都爬行完,然后再从A1页面发现的下一层链接,爬行到A2 ,A3,A4,从理论上说,无论是深度优先还是广度优先,只要给蜘蛛足够的时间,都能爬完整个互联网。在实际工作中,蜘蛛的带宽资源 ,时间都不是无限的。也不可能爬完所有页面。实际上最大的搜索引擎也只是爬行和收录了互联网的一小部分。
版权声明
本文仅代表作者观点,不代表本站立场。
本文系作者授权发表,未经许可,不得转载。
本文地址:/yunying/SEO/121468.html