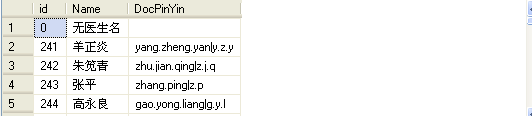
数据库中union 与union all 的区别
今天晚上在操作两个表时才发现两个的区别。呵呵。
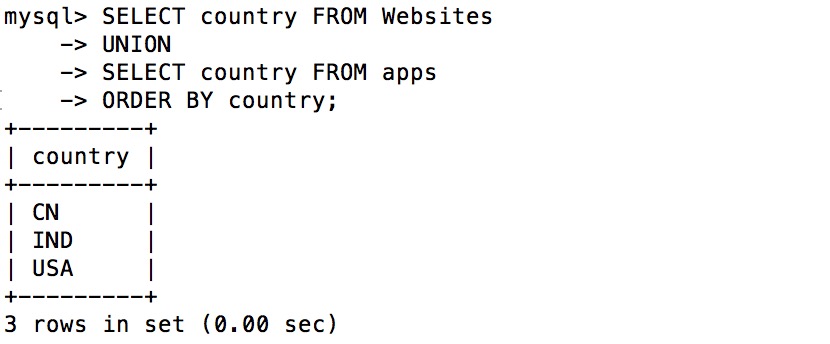
union 将两个表连接后删除其重复的项;
union all 将两个表连接都不删除其重复的项。
这个东东很简单。不过也记录一哈 。实在是一个小小的收获。
补充资料:
数据库中,UNION和UNION ALL都是将两个结果集合并为一个,但这两者从使用和效率上来说都有所不同。
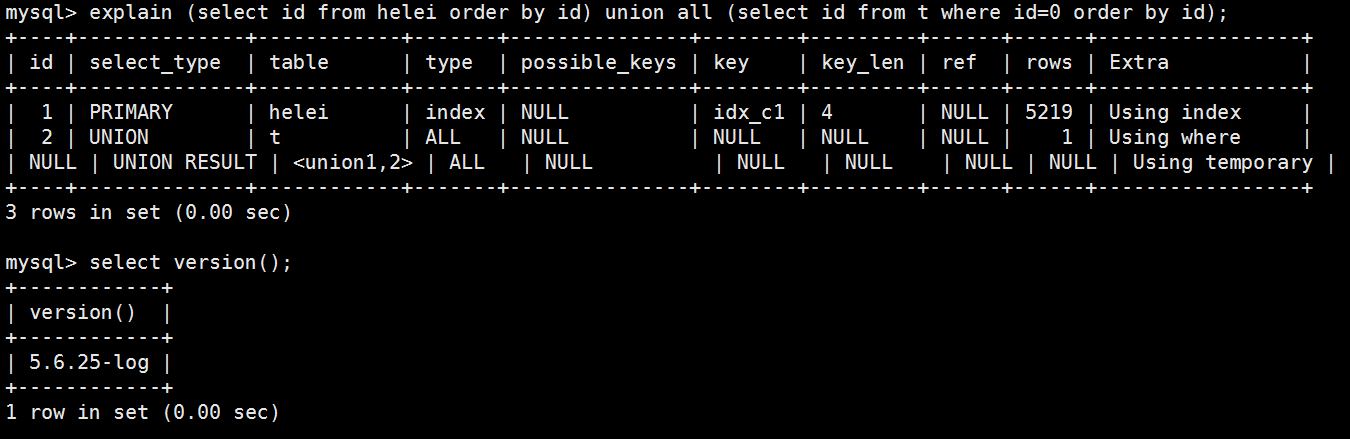
UNION在进行表链接后会筛选掉重复的记录,所以在表链接后会对所产生的结果集进行排序运算,删除重复的记录再返回结果。实际大部分应用中是不会产生重复的记录,最常见的是过程表与历史表UNION。如:
select * from users1 union select * from user2
这个SQL在运行时先取出两个表的结果,再用排序空间进行排序删除重复的记录,最后返回结果集,如果表数据量大的话可能会导致用磁盘进行排序。
而UNION ALL只是简单的将两个结果合并后就返回。这样,如果返回的两个结果集中有重复的数据,那么返回的结果集就会包含重复的数据了。
从效率上说,UNION ALL 要比UNION快很多,所以,如果可以确认合并的两个结果集中不包含重复的数据的话,那么就使用UNION ALL,如下:
select * from user1 union all select * from user2
union 将两个表连接后删除其重复的项;
union all 将两个表连接都不删除其重复的项。
这个东东很简单。不过也记录一哈 。实在是一个小小的收获。
补充资料:
数据库中,UNION和UNION ALL都是将两个结果集合并为一个,但这两者从使用和效率上来说都有所不同。
UNION在进行表链接后会筛选掉重复的记录,所以在表链接后会对所产生的结果集进行排序运算,删除重复的记录再返回结果。实际大部分应用中是不会产生重复的记录,最常见的是过程表与历史表UNION。如:
select * from users1 union select * from user2
这个SQL在运行时先取出两个表的结果,再用排序空间进行排序删除重复的记录,最后返回结果集,如果表数据量大的话可能会导致用磁盘进行排序。
而UNION ALL只是简单的将两个结果合并后就返回。这样,如果返回的两个结果集中有重复的数据,那么返回的结果集就会包含重复的数据了。
从效率上说,UNION ALL 要比UNION快很多,所以,如果可以确认合并的两个结果集中不包含重复的数据的话,那么就使用UNION ALL,如下:
select * from user1 union all select * from user2
版权声明
本文仅代表作者观点,不代表本站立场。
本文系作者授权发表,未经许可,不得转载。
本文地址:/shujuku/shujukujiqiao/101670.html