Oracle数据库由dataguard备库引起的log file sync等待问题
目录
导读:
最近数据库经常出现会话阻塞的报警,过一会又会自动消失,昨天晚上恰好发生了一次,于是赶紧进行了查看,不看不知道,一看吓一跳,发现是由dataguard引起的log file sync等待。我们知道,通常log file sync等待都是由频繁写日志造成的,这次居然是由DG环境引起的。
(一)问题描述
数据库:Oracle 11.2.0.4,单机版,有Dataguard环境
操作系统:centos 7.4
通过zabbix监控到的会话阻塞信息如下图,这里是自定义的监控,解释如下:
用户usera,其session id为2663,session serial为27727,该会话未在执行SQL语句,但是却一直处于非空闲等待,等待的事件为log file sync,一共等待了548s

(二)分析
查看报警期间的历史会话信息:
select sample_time, session_id,session_serial#,session_type,user_id,sql_id,sql_plan_operation,event,
blocking_session,blocking_session_serial#,PROGRAM,MACHINE
from v$active_session_history a
where a.sample_time > to_date('2020-11-25 20:40:00','yyyy-mm-dd hh24:mi:ss')
and a.sample_time < to_date('2020-11-25 20:59:00','yyyy-mm-dd hh24:mi:ss')
and blocking_session is not null
order by a.sample_time;
可以看到,会话1333,2191,2663均被会话1331阻塞了,等待事件是log file sync,它们在等待的会话为1311。

查询1331会话信息,发现是日志写进程LGWR,1311会话不再被其它会话阻塞,可以判定该会话为阻塞源头,1331会话的等待事件是LGWR-LNS wait on channel。
select sample_time, session_id,session_serial#,session_type,user_id,sql_id,event,
blocking_session_status,blocking_session,PROGRAM,MACHINE
from v$active_session_history a
where a.sample_time > to_date('2020-11-25 20:40:00','yyyy-mm-dd hh24:mi:ss')
and a.sample_time < to_date('2020-11-25 20:59:00','yyyy-mm-dd hh24:mi:ss')
and a.session_id = 1331
order by a.sample_time;

在本案例中,一共出现了2种类型的非空闲等待事件:
- log file sync
- LGWR-LNS wait on channel(阻塞源头)
什么是log file sync:当用户提交一个事务之后就开始等待log file sync,直到LGWR进程完成了对SCN的传播和对应重做日志的写入操作。所以log file sync的等待时间是由重做日志I/O时间和SCN传播时间两部分构成的,如果还使用了DataGuard,且日志传送时使用了同步+确认(SYNC+AFFRIM)选项时,那么LGWR还需在用户提交事务之后将重做日志信息传递到远程备库节点。总结一下,log file sync的计算公式如下:
用户进程log file sync等待时间 = LGWR执行重做日志I/O时间 + SCN传播时间 + LGWR传送重做日志到备库的时间。
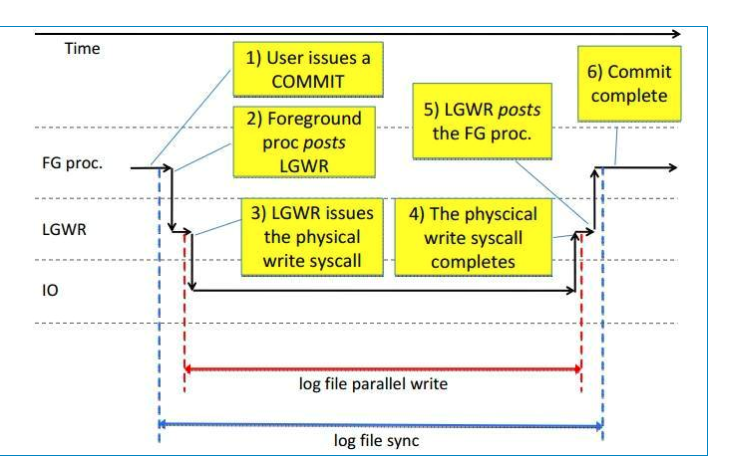
在数据库实例中,log file sync的等待步骤如下:
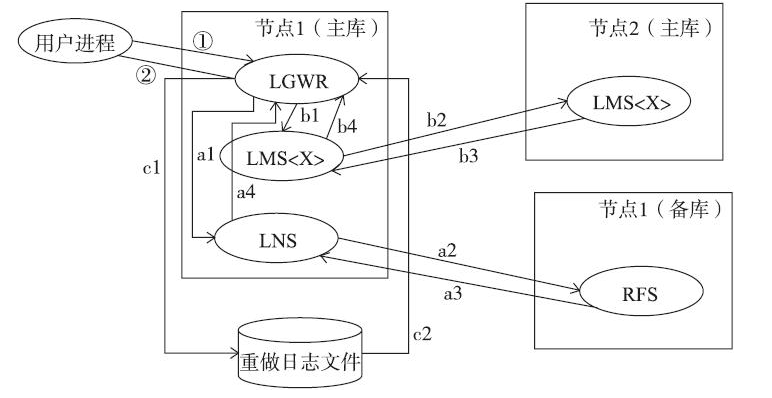
步骤①和②时所经历的时间就是log file sync所经历的时间。a1~a4是LGWR传送重做日志到备库的过程,b1~b4是LGWR传播SCN的过程,c1~c2是LGWR将重做日志写入到重做日志文件的过程。
a1~a4代表LGWR传送重做日志到DataGuard备库,过程如下:
a1:LGWR将事务对应的重做信息发送给本地节点的LNS(network server)进程
a2:LNS进程通过网络将重做信息发送给备库的RFS(remote file server)进程
a3:RFS进程将重做日志信息写入到备库的备用重做日志文件(Standby redo log),返回消息给主库的LNS进程
a4:主库的LNS进程通知LGWR进程重做信息已经写入到备库的备用重做日志文件
b1~b4代表LGWR传播SCN,SCN是数据库内部的时钟,不重复,单项增长,SCN是针对数据库的,不是针对实例的,也就是说,对于RAC数据库,虽然有多个实例,这些实例会使用相同的SCN,但是每个实例都可以进行各自的任务,这就意味着实例之间需要传播SCN。对于分布式数据库(例如,使用了DB Link),也同样存在着同步SCN的概念。同步SCN的过程如下:
b1:LGWR进程将事务提交的SCN发送给本地的一个LMS进程
b2:本地节点的LMS进程将包含了SCN的消息发送给所有远程节点的LMS进程
b3:所有远程节点的LMS进程接受到了SCN消息并反馈给本地节点的LMS进程
b4:本地节点的LMS进程通知LGWR,所有远程节点都受到了事务的SCN
c1~c2代表LGWR执行重做日志写I/O。过程如下:
c1:LGWR进程将redo buffer cache中的日志写入到online redo log
c2:写完之后LGWR会收到通知已完成
在分析完log file sync等待事件的过程之后,基本上可以知道其形成原因了。然而,新的问题又来了,log file sync等待由3部分原因构成,在我的环境中,到底是LGWR执行重做日志比较慢,还是SCN传播时间存在异常等待,还是LGWR传送重做日志到备库存在性能瓶颈,这个时候我们就需要确认log file sync的并发现象了,我们继续分析。
(1)由LGWR执行重做日志I/O引起的log file sync
如果是由于LGWR将日志写入到online redo log引起的I/O问题,往往会伴随着log file parallel write等待事件出现,也就是说,如果log file sync和log file parallel write一起出现,那么往往是存放在线日志文件的磁盘I/O出问题了,有可能是磁盘吞吐量较差,也有可能是频繁的小I/O操作,磁盘I/O问题的主要解决方案如下:
- 优化了redo日志的I/O性能,尽量使用快速磁盘,不要把redo log file存放在raid 5的磁盘上;
- 加大日志缓冲区(log buffer);
- 使用批量提交,减少提交的次数;
(2)由SCN传播引起的log file sync
由SCN传播引起的log file sync等待事件几乎没有见过,个人觉得SCN传播引起log file sync的概率较小,可以忽略
SQL> SELECT NAME FROM v$event_name a WHERE a.name LIKE '%SCN%' OR a.name LIKE '%LMS%'; NAME ---------------------------------------------------------------- retry contact SCN lock master ges master to get established for SCN op
(3)由LGWR传送重做日志到备库引起的log file sync
需要特别注意的是,只有在LOG_ARCHIVE_DEST_n参数中使用了"SYNC,AFFIRM"属性时,log file sync等待事件才会与LGWR传送日志有关,如果使用了其它属性,不用考虑。
LNS进程DataGuard环境中主库用来传送日志到备库的进程,查看所有与之相关的等待事件。
SQL> SELECT NAME FROM v$event_name a WHERE a.name LIKE '%LNS%'; NAME ---------------------------------------------------------------- LNS wait on ATTACH LNS wait on SENDREQ LNS wait on DETACH LNS wait on LGWR LGWR wait on LNS LNS ASYNC archive log LNS ASYNC dest activation LNS ASYNC end of log LNS simulation latency wait LGWR-LNS wait on channel
回过头,再次查看我们的生产环境的问题,是log file sync伴随着LGWR-LNS wait on channel出现,再次确认数据库的参数信息,发现数据库运行在最大可用模式,备库采用了同步(sync)方式传送数据。
SQL> select name,open_mode,database_role,protection_mode,protection_level from v$database;
NAME OPEN_MODE DATABASE_ROLE PROTECTION_MODE PROTECTION_LEVEL
--------- -------------------- ---------------- -------------------- --------------------
ORCL2 READ WRITE PRIMARY MAXIMUM AVAILABILITY MAXIMUM AVAILABILITY
SQL> show parameter log
NAME TYPE VALUE
----------------------------- ------- ----------------------------------------------------------------------------------------------------
log_archive_dest_2 string SERVICE=adg_orcl LGWR SYNC VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE)
DB_UNIQUE_NAME=adg_orcl
再进一步分析"LGWR-LNS wait on channel"等待事件:
什么是LGWR-LNS wait on channel:这个等待事件监视LGWR或LNS进程等待在KSR通道上接收消息所花费的时间(This wait event monitors the amount of time spent by the log writer (LGWR) process or the network server processes waiting to receive messages on KSR channels. Data Guard Wait Events (Doc ID 233491.1) )。
KSR通道的解释:https://docs.oracle.com/en/database/oracle/oracle-database/12.2/refrn/DBA_HIST_CHANNEL_WAITS.html#GUID-682C58F4-5787-4C8E-844C-9DFE04612BDD。
可以断定,数据库的异常等待是由于主库的LNS进程同步传送在线日志信息给DG环境引起的,且引起的瓶颈在备库端。想到我们的主库是高配的物理服务器,备库是低配的云主机(虚拟机),出现这种问题也就不足为奇了。
(三)解决方案
使用异步方式传送日志信息,修改日志传送方式为异步(async)传送
SQL> alter system set log_archive_dest_2= SERVICE="adg_orcl" LGWR ASYNC VALID_FOR=(all_logfiles, primary_role) DB_UNIQUE_NAME="adg_orcl" scope=both; -- 重新启用通道 SQL> alter system set log_archive_dest_state_2= defer; SQL> alter system set log_archive_dest_state_2= enable;
到此这篇关于Oracle数据库由dataguard备库引起的log file sync等待的文章就介绍到这了,更多相关Oracle dataguard备库引起的log file sync等待内容请搜索潘少俊衡以前的文章或继续浏览下面的相关文章希望大家以后多多支持潘少俊衡!
版权声明
本文仅代表作者观点,不代表本站立场。
本文系作者授权发表,未经许可,不得转载。
本文地址:/shujuku/oracle/97509.html