Redis集群的相关详解
注意!要求使用的都是redis3.0以上的版本,因为3.0以上增加了redis集群的功能。
1.redis介绍
1.1什么是redis
Redis是用C语言开发的一个开源的高性能键值对(key-value)的非关系型数据库。通过多种键值数据类型来适应不同场景下的存储需求,目前支持的键值数据类型有:
字符串,散列,列表,集合,有序集合
2.2应用场景
缓存(数据查询、短连接、新闻内容、商品内容等等)。(最多使用)
分布式集群架构中的session分离。
聊天室的在线好友列表。
任务队列。(秒杀、抢购、12306等等)
应用排行榜。
网站访问统计。
数据过期处理(可以精确到毫秒)
2.Redis集群的介绍
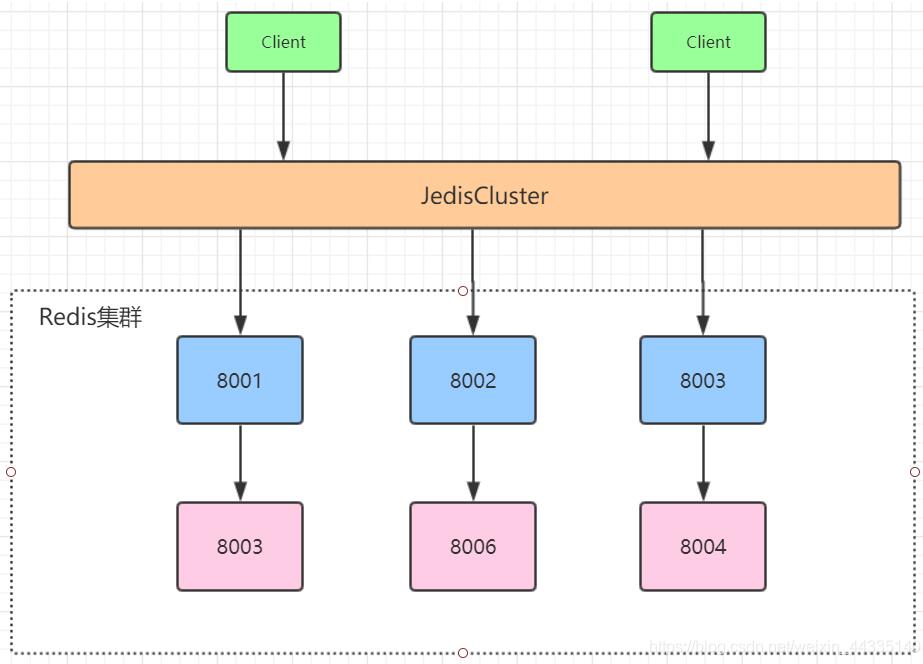
2.1Redis集群的架构


Redis 集群中内置了 16384 个哈希槽,redis-cluster把所有的物理节点映射到[0-16383]slot上,cluster 负责维护。当需要在 Redis 集群中放置一个 key-value 时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点
2.2 Redis集群的特点
当Redis集群启动后,就自动在多个节点间做好分片,同时提供了分片之间的可用性:即当一部分redis节点故障或者网络中断后,集群还有从节点可以替代主节点继续工作,但如果大面积的节点故障,那集群就不可用了。
Redis集群提供了:
自动将16384个数据槽点切分到多个Redis节点中
当一部分节点故障或不可达,集群依然能继续工作
2.3 Redis集群的TCP端口
集群的每个节点都需要建立两个TCP连接,监听这两个端口:
客户端端口(一般是6379):需要对所有客户端和集群节点开放,用于接收客户端指令,且集群节点需要通过该端口向客户端转移数据。
集群总线端口(一般是6379+10000):只需要对集群中的所有节点开放,用于节点之间通过二进制协议通信。各节点通过集群总线检测故障节点,更新配置等,而客户端是不能使用该端口的。
2.4 Redis集群数据的分片
Redis集群使用的是哈希槽,有16384个哈希槽,决定一个key分配到哪个槽的算法:计算该key的CRC16,结果再模16384.
集群中的每个节点负责一部分哈希槽,比如集群中有3个节点,则:
- 节点A存储的哈希槽范围是:0 – 5500
- 节点B存储的哈希槽范围是:5501 – 11000
- 节点C存储的哈希槽范围是:11001 – 16384
这样的分布方式方便节点的添加和删除。比如,需要新增一个节点D,只需要把A、B、C中的部分哈希槽数据移到D节点。同样,如果希望在集群中删除A节点,只需要把A节点的哈希槽的数据移到B和C节点,当A节点的数据全部被移走后,A节点就可以完全从集群中删除。
因为把哈希槽从一个节点移到另一个节点是不需要停机的,所以,增加或删除节点,或更改节点上的哈希槽,也是不需要停机的。
如果多个key都属于一个哈希槽,集群支持通过一个命令(或事务, 或lua脚本)同时操作这些key。通过“哈希标签”的概念,用户可以让多个key分配到同一个哈希槽。如果key含有大括号”{}”,则只有大括号中的字符串会参与哈希,比如”this{foo}”和”another{foo}”这2个key会分配到同一个哈希槽,所以可以在一个命令中同时操作他们。
2.5 Redis集群的主从模式
每个哈希槽都有一个主节点和多个从节点。
举例:如果有六个节点,则分A,B,C三个为主节点,A1,B1,C1三个为对应的从节点,当A发生故障后,集群会提升A1为主节点,A1会继承A节点的数据,其实A1就相当于A的一个副本,让集群继续工作。
2.5.1 redis-cluster投票:容错

(1)投票过程是集群中所有主节点参与,如果半数以上主节点与故障主节点通信超过(cluster-node-timeout),认为当前该主节点挂掉.
(2):什么时候整个集群不可用(cluster_state:fail)?
a:如果集群任意主节点挂掉,且没有从节点.集群进入fail状态,也可以理解成集群的slot映射[0-16383]不完成时进入fail状态.
b:如果集群超过半数以上主节点挂掉,无论是否有从节点,集群都进入fail状态.
ps:当集群不可用时,所有对集群的操作做都不可用,收到((error) CLUSTERDOWN The cluster is down)错误。
2.6 Redis集群的一致性保证
Redis集群不能保证强一致性。一些已经向客户端确认写成功的操作,会在某些不确定的情况下丢失。
产生写操作丢失的第一个原因,是因为主从节点之间使用了异步的方式来同步数据。
一个写操作是这样一个流程:
- 1)客户端向主节点B发起写的操作
- 2)主节点B回应客户端写操作成功
- 3)主节点B向它的从节点B1,B2,B3同步该写操作
从上面的流程可以看出来,主节点B并没有等从节点B1,B2,B3写完之后再回复客户端这次操作的结果。所以,如果主节点B在通知客户端写操作成功之后,但同步给从节点之前,主节点B故障了,其中一个没有收到该写操作的从节点会晋升成主节点,该写操作就这样永远丢失了。
节点超时(node timeout):对集群来说非常重要,当达到了这个节点超时的时间之后,主节点被认为已经宕机,可以用它的一个从节点来代替。同样,在节点超时时,如果主节点依然不能联系到其他主节点,它将进入错误状态,不再接受写操作。
2.7 Redis集群的参数配置
在redis.conf中的一些参数说明:
cluster-enabled
如果配置”yes”则开启集群功能,此redis实例作为集群的一个节点,否则,它是一个普通的单一的redis实例。
cluster-config-file :
注意:虽然此配置的名字叫“集群配置文件”,但是此配置文件不能人工编辑,它是集群节点自动维护的文件,主要用于记录集群中有哪些节点、他们的状态以及一些持久化参数等,方便在重启时恢复这些状态。通常是在收到请求之后这个文件就会被更新。
cluster-node-timeout :
这是集群中的节点能够失联的最大时间,超过这个时间,该节点就会被认为故障。如果主节点超过这个时间还是不可达,则用它的从节点将启动故障迁移,升级成主节点。注意,任何一个节点在这个时间之内如果还是没有连上大部分的主节点,则此节点将停止接收任何请求。
cluster-slave-validity-factor :
如果设置成0,则无论从节点与主节点失联多久,从节点都会尝试升级成主节点。如果设置成正数,则cluster-node-timeout乘以cluster-slave-validity-factor得到的时间,是从节点与主节点失联后,此从节点数据有效的最长时间,超过这个时间,从节点不会启动故障迁移。假设cluster-node-timeout=5,cluster-slave-validity-factor=10,则如果从节点跟主节点失联超过50秒,此从节点不能成为主节点。注意,如果此参数配置为非0,将可能出现由于某主节点失联却没有从节点能顶上的情况,从而导致集群不能正常工作,在这种情况下,只有等到原来的主节点重新回归到集群,集群才恢复运作。
cluster-migration-barrier
:主节点需要的最小从节点数,只有达到这个数,主节点失败时,它从节点才会进行迁移。更详细介绍可以看本教程后面关于副本迁移到部分。
cluster-require-full-coverage
则整个集群停止接受操作;如果此参数设置为”no”,则集群依然为可达节点上的key提供读操作。
以上所述是小编给大家介绍的Redis集群的相关详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对潘少俊衡网站的支持!
版权声明
本文仅代表作者观点,不代表本站立场。
本文系作者授权发表,未经许可,不得转载。
本文地址:/shujuku/Redis/103319.html