Postgres bytea类型 转换及查看操作
一开发表里的列类型为 bytea ,可是它select出来的时候又不是想要的结果:
在postgres配置文件里修改参数
bytea_output = 'escape'
这个默认是hex类型的,修改成escape。
查看的时候还是不是想要的结果:
select encode(data::bytea,'hex') from data_from_target limit 1;
补充:PostgreSQL的数据类型及日常实践笔记
数据类型是编程语言中,在其数据结构上定义的相同值类型的集合以及对该相同值集合的一组操作。而数据类型的值存储离不开变量,因此变量的一个作用就是使用它来存储相同值集的数据类型。数据类型决定了如何将代表这些值的集合存储在计算机的内存中。变量一般遵循先声明后使用的原则。而在数据库中,变量就是字段,用字段来表示一组相同值类型的集合,其实也是先声明后使用的原则。
PostgreSQL支持丰富的数据类型,包括一般的数据类型和非常规的数据类型。一般数据类型包括数值型,货币类型,字符类型,日期类型,布尔类型,枚举类型等,非常规数据类型包括二进制数据类型,几何类型,网络地址类型,位串类型,文本搜索类型,UUID类型,XML类型,JSON类型,数组类型,复合类型,范围类型,Domain类型,OID类型,pg_lsn类型和pseudo-Types类型。
一 数值类型*
1.1整型
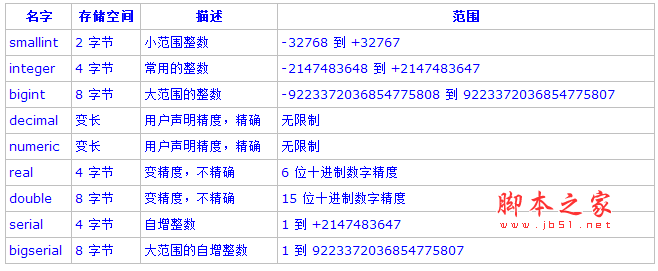
PostgreSQL中的整型类型有小整型,整型,大整型,用 smallint,integer,和bigint表示,虽然三个都可以存储相同的数据类型,但是它们各自的存储大小和存储范围却不相同。见下表:
| 名称 | 描述 | 存储空间 | 范围 |
|---|---|---|---|
| SMALLINT | 小范围整数,别名为INT2。 | 2字节 | -32,768 - +32,767 |
| INTEGER | 常用的整数,别名为INT4。 | 4字节 | -2,147,483,648 - +2,147,483,647 |
| BIGINT | 大范围的整数,别名为INT8。 | 8字节 | -9,223,372,036,854,775,808 - 9,223,372,036,854,775,807 |
如下示例所示,在PostgreSQL中,smallint,integer,bigint 数据类型可以使用 int2,int4,int8的扩展写法来标识。
示例:
hrdb=# --创建整型数据类型的表
hrdb=# CREATE TABLE IF NOT EXISTS tab_num(v1 smallint,v2 smallint,v3 int,v4 int,v5 bigint,v6 bigint);
CREATE TABLE
hrdb=# --表字段注释
hrdb=# COMMENT ON COLUMN tab_num.v1 IS '小整型最小范围';
COMMENT
hrdb=# COMMENT ON COLUMN tab_num.v2 IS '小整型最大范围';
COMMENT
hrdb=# COMMENT ON COLUMN tab_num.v3 IS '整型最小范围';
COMMENT
hrdb=# COMMENT ON COLUMN tab_num.v4 IS '整型最大范围';
COMMENT
hrdb=# COMMENT ON COLUMN tab_num.v5 IS '大整型最小范围';
COMMENT
hrdb=# COMMENT ON COLUMN tab_num.v6 IS '大整型最大范围';
COMMENT
hrdb=# --描述数据类型
hrdb=# \d+ tab_num
Table "public.tab_num"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+----------+-----------+----------+---------+---------+--------------+----------------
v1 | smallint | | | | plain | | 小整型最小范围
v2 | smallint | | | | plain | | 小整型最大范围
v3 | integer | | | | plain | | 整型最小范围
v4 | integer | | | | plain | | 整型最大范围
v5 | bigint | | | | plain | | 大整型最小范围
v6 | bigint | | | | plain | | 大整型最大范围
hrdb=# --插入不同整型的范围数值
hrdb=# INSERT INTO tab_num
hrdb-# VALUES (-32768,
hrdb(# 32767,
hrdb(# -2147483648,
hrdb(# 2147483647,
hrdb(# -9223372036854775808,
hrdb(# 9223372036854775807);
INSERT 0 1
hrdb=# --查询结果
hrdb=# SELECT * FROM tab_num;
v1 | v2 | v3 | v4 | v5 | v6
--------+-------+-------------+------------+----------------------+---------------------
-32768 | 32767 | -2147483648 | 2147483647 | -9223372036854775808 | 9223372036854775807
(1 row)
如上所示,查询的结果为插入不同整型范围的最值,也说明不同整型范围的边界都是被包括的。在实际生产场景中,SMALLINT、INTEGER和BIGINT类型存储各种范围的数字,也就是整数。当试图存储超出范围以外的数值将会导致错误。
常用的类型是INTEGER,因为它提供了在范围、存储空间、性能之间的最佳平衡。一般只有取值范围确定不超过SMALLINT的情况下,才会使用SMALLINT类型。而只有在INTEGER的范围不够的时候才使用BIGINT,因为前者相对要快。
除此之外,创建表也可以使用 int2,int4,int8来代表 smallint,integer,bigint。如下示例所示:
hrdb=# /*
hrdb*# smallint,integer,bigint
hrdb*# 数据类型分别使用
hrdb*# int2,int4,int8代替
hrdb*# */
hrdb-# CREATE TABLE IF NOT EXISTS tab_numint(v1 int2,v2 int2,v3 int4,v4 int4,v5 int8,v6 int8);
CREATE TABLE
hrdb=# --描述表定义及数据类型
hrdb=# \d+ tab_numint
Table "public.tab_numint"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+----------+-----------+----------+---------+---------+--------------+-------------
v1 | smallint | | | | plain | |
v2 | smallint | | | | plain | |
v3 | integer | | | | plain | |
v4 | integer | | | | plain | |
v5 | bigint | | | | plain | |
v6 | bigint | | | | plain |
1.2任意精度类型和浮点类型
任意精度类型 numeric、decimal可以存储范围大的数字,存储大小为可变大小,小数点前最多131072位数字,小数点后最多16383位。它可以使用类似浮点类型,将小数精确到保留几位,也可以参与计算可以得到准确的值,但是相比于浮点类型,它的计算比较慢。通常 numeric被推荐使用于存储货币金额或其它要求计算准确的值。详细见下表:
| 名称 | 描述 | 存储空间 | 范围 |
|---|---|---|---|
| NUMERIC[(p[,s])],DECIMAL[(p[,s])] | 精度p取值范围为[1,1000],标度s取值范围为[0,p]。说明: p为总位数,s为小数位数 | 用户声明精度。每四位(十进制位)占用两个字节,然后在整个数据上加上八个字节的额外开销。 | 未指定精度的情况下,小数点前最大131,072位,小数点后最大16,383位。 |
| real | 可变精度 | 4个字节 | 6位小数精度 |
| double precision | 可变精度 | 8个字节 | 15位小数精度 |
示例:任意精度类型
hrdb=# --任意精度类型示例
hrdb=# CREATE TABLE IF NOT EXISTS tab_any_precision(col1 numeric(10,4),col2 decimal(6,4),col3 real,col4 double precision,col5 float4,col6 float8);
CREATE TABLE
hrdb=# --字段注释
hrdb=# COMMENT ON COLUMN tab_any_precision.col1 IS '表示整数最大位数为6,小数仅保留4位';
COMMENT
hrdb=# COMMENT ON COLUMN tab_any_precision.col2 IS '表示整数最大位数为2,小数保留4位';
COMMENT
hrdb=# COMMENT ON COLUMN tab_any_precision.col3 IS '表示可变的6位精度的数值类型';
COMMENT
hrdb=# COMMENT ON COLUMN tab_any_precision.col4 IS '表示可变的15位精度的数值类型';
COMMENT
hrdb=# COMMENT ON COLUMN tab_any_precision.col5 IS '同real';
COMMENT
hrdb=# COMMENT ON COLUMN tab_any_precision.col6 IS '同double precision';
COMMENT
hrdb=# --查看表定义
hrdb=# \d+ tab_any_precision
Table "public.tab_any_precision"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+------------------+-----------+----------+---------+---------+--------------+-----------------------------------
col1 | numeric(10,4) | | | | main | | 表示整数最大位数为6,小数仅保留4位
col2 | numeric(6,4) | | | | main | | 表示整数最大位数为2,小数保留4位
col3 | real | | | | plain | | 表示可变的6位精度的数值类型
col4 | double precision | | | | plain | | 表示可变的15位精度的数值类型
col5 | real | | | | plain | | 同real
col6 | double precision | | | | plain | | 同double precision
hrdb=# --插入任意精度测试
hrdb=# INSERT INTO tab_any_precision
hrdb-# VALUES(202004.26,20.2004,20.200426,20.203415341535157,20.200426,20.203415341535157);
INSERT 0 1
hrdb=# INSERT INTO tab_any_precision
hrdb-# VALUES(202004.26105,20.20045,20.2004267,20.2034153415351573,20.2004264,20.2034153415351575);
INSERT 0 1
hrdb=# --可以发现col1和col2小数部分可以超过4位,但是读取仅仅保留4位,并遵循四舍五入的原则,如下结果
hrdb=# SELECT * FROM tab_any_precision;
col1 | col2 | col3 | col4 | col5 | col6
-------------+---------+---------+------------------+---------+------------------
202004.2600 | 20.2004 | 20.2004 | 20.2034153415352 | 20.2004 | 20.2034153415352
202004.2611 | 20.2005 | 20.2004 | 20.2034153415352 | 20.2004 | 20.2034153415352
(2 rows)
hrdb=# /*
hrdb*# 如果 col1 插入的整数最大位数超过6,将会报错。
hrdb*# 如果 col2 插入的整数最大位数超过2,将会报错。
hrdb*# real 和 double precision 没有限制。
hrdb*# */
hrdb-# INSERT INTO tab_any_precision
hrdb-# VALUES(2020042.610,20.2004,20.2004267,20.2034153415351573,20.2004264,20.2034153415351575);
ERROR: numeric field overflow
DETAIL: A field with precision 10, scale 4 must round to an absolute value less than 10^6.
hrdb=# INSERT INTO tab_any_precision
hrdb-# VALUES(202004.26105,202.200,20.2004267,20.2034153415351573,20.2004264,20.2034153415351575);
ERROR: numeric field overflow
DETAIL: A field with precision 6, scale 4 must round to an absolute value less than 10^2.
hrdb=#
1.3 序列类型
SMALLSERIAL,SERIAL和BIGSERIAL类型不是真正的数据类型,只是为在表中设置唯一标识做的概念上的便利。因此,创建一个整数字段,并且把它的缺省数值安排为从一个序列发生器读取。应用了一个NOT NULL约束以确保NULL不会被插入。在大多数情况下用户可能还希望附加一个UNIQUE或PRIMARY KEY约束避免意外地插入重复的数值,但这个不是自动的。最后,将序列发生器从属于那个字段,这样当该字段或表被删除的时候也一并删除它。
| 名称 | 描述 | 存储空间 | 范围 |
|---|---|---|---|
| SMALLSERIAL | 二字节序列整型 | 2字节 | 1 - 32,767 |
| SERIAL | 四字节序列整型 | 4字节 | 1 - 2,147,483,647 |
| BIGSERIAL | 八字节序列整型 | 8字节 | 1 - 9,223,372,036,854,775,807 |
示例:
hrdb=# --创建序列类型表
hrdb=# CREATE TABLE tab_serial(col1 smallserial,col2 serial,col3 bigserial);
CREATE TABLE
hrdb=# --字段注释
hrdb=# COMMENT ON COLUMN tab_serial.col1 IS '小整型序列,从1开始,最大值为32767';
COMMENT
hrdb=# COMMENT ON COLUMN tab_serial.col2 IS '小整型序列,从1开始,最大值为2147483647';
COMMENT
hrdb=# COMMENT ON COLUMN tab_serial.col3 IS '小整型序列,从1开始,最大值为9223372036854775807';
COMMENT
hrdb=# --查看表定义
hrdb=# \d+ tab_serial
Table "public.tab_serial"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+----------+-----------+----------+------------------------------------------+---------+--------------+--------------------------------------------------
col1 | smallint | | not null | nextval('tab_serial_col1_seq'::regclass) | plain | | 小整型序列,从1开始,最大值为32767
col2 | integer | | not null | nextval('tab_serial_col2_seq'::regclass) | plain | | 小整型序列,从1开始,最大值为2147483647
col3 | bigint | | not null | nextval('tab_serial_col3_seq'::regclass) | plain | | 小整型序列,从1开始,最大值为9223372036854775807
hrdb=# --插入数据
hrdb=# INSERT INTO tab_serial VALUES(1,1,1);
INSERT 0 1
hrdb=# INSERT INTO tab_serial VALUES(32767,2147483647,9223372036854775807);
INSERT 0 1
hrdb=# --如果插入的值大于序列整型值的范围,将会整型类型越界的ERROR
hrdb=# INSERT INTO tab_serial VALUES(32767,2147483647,9223372036854775808);
ERROR: bigint out of range
hrdb=# INSERT INTO tab_serial VALUES(32767,2147483648,9223372036854775807);
ERROR: integer out of range
hrdb=# INSERT INTO tab_serial VALUES(32768,2147483647,9223372036854775807);
ERROR: smallint out of range
hrdb=# --当然,既然是序列类型,那可以插入默认值
hrdb=# INSERT INTO tab_serial
hrdb-# VALUES(default,default,default);
INSERT 0 1
通过上述示例,可以知道 smallserial,serial,bigserial相当于先创建一个序列,然后在创建表分别指定不同的整型数据类型smallint,integer,bigint。如下示例:
hrdb=# --先创建序列
hrdb=# CREATE SEQUENCE IF NOT EXISTS serial_small
hrdb-# INCREMENT BY 1
hrdb-# START WITH 1
hrdb-# NO CYCLE;
CREATE SEQUENCE
hrdb=# --再创建表
hrdb=# CREATE TABLE IF NOT EXISTS tab_test_serial(
hrdb(# col1 smallint default nextval('serial_small'),
hrdb(# col2 integer default nextval('serial_small'),
hrdb(# col3 bigint default nextval('serial_small')
hrdb(# );
CREATE TABLE
hrdb=# --插入数据
hrdb=# INSERT INTO tab_test_serial VALUES(default);
INSERT 0 1
hrdb=# --查询数据
hrdb=# SELECT * FROM tab_test_serial ;
col1 | col2 | col3
------+------+------
1 | 2 | 3
(1 row)
二 货币数据类型
货币类型存储带有固定小数精度的货币金额。
关于货币数据类型的详细信息如下表:
| 名称 | 存储容量 | 描述 | 范围 |
|---|---|---|---|
| money | 8 字节 | 货币金额 | -92233720368547758.08 到 +92233720368547758.07 |
示例:
hrdb=# --创建货币数据类型表
hrdb=# CREATE TABLE IF NOT EXISTS tab_money(amounts money);
CREATE TABLE
hrdb=# --字段注释
hrdb=# COMMENT ON COLUMN tab_money.amounts IS '金额';
COMMENT
hrdb=# --插入数值
hrdb=# INSERT INTO tab_money VALUES('20.00');
INSERT 0 1
hrdb=# --查询数据
hrdb=# SELECT * FROM tab_money;
amounts
---------
$20.00
(1 row)
这里需要注意的是,如果插入的货币数据类型的金额没有明确指定货币表示符号,那么默认输出本区域货币符号,如上示例所示的20.00输出为$20.00。
如果是人民币,那么如何处理呢?
解决方法有两种,第一种,使用translate函数;第二种,修改本地区域货币符号显示参数。
hrdb=# --方法一:直接使用translate函数将 $ 符号转换为 ¥ 符号 hrdb=# SELECT translate(amounts::varchar,'$','¥') FROM tab_money; translate ----------- ¥20.00 (1 row) hrdb=# --方法二:修改区域货币符号显示参数 hrdb=# --查看本地区域货币符号显示参数 hrdb=# show lc_monetary ; lc_monetary ------------- en_US.UTF-8 (1 row) hrdb=# --修改区域货币符号显示参数 hrdb=# ALTER SYSTEM SET lc_monetary = 'zh_CN.UTF-8'; ALTER SYSTEM hrdb=# --重新加载动态参数 hrdb=# SELECT pg_reload_conf(); pg_reload_conf ---------------- t (1 row) hrdb=# --重新查看本地区域货币符号显示参数 hrdb=# show lc_monetary; lc_monetary ------------- zh_CN.UTF-8 (1 row) hrdb=# --重新查询数据 hrdb=# SELECT * FROM tab_money; amounts --------- ¥20.00 (1 row)
货币符号作为特殊的数据类型,需要注意计算方式,以防止发生精度丢失的问题。
这种问题解决方式需要将货币类型转换为 numeric 类型以避免精度丢失。
hrdb=# INSERT INTO tab_money VALUES('20.22');
INSERT 0 1
hrdb=# SELECT * FROM tab_money ;
amounts
---------
¥20.00
¥20.22
(2 rows)
hrdb=# --货币数据类型避免精度丢失的解决方法
SELECT amounts::numeric::float8 FROM tab_money;
amounts
---------
20
20.22
温馨提示:
当一个money类型的值除以另一个money类型的值时,结果是double precision(也就是,一个纯数字,而不是money类型);在运算过程中货币单位相互抵消
三 布尔类型
PostgreSQL提供标准的boolean值,boolean的状态为 true或者false和unknown,如果是unknown状态表示boolean值为null。
| 名称 | 描述 | 存储空间 | 取值 |
|---|---|---|---|
| BOOLEAN | 布尔类型 | 1字节 | true:真 false:假 null:未知(unknown |
示例:
hrdb=# --创建boolean类型表
hrdb=# CREATE TABLE IF NOT EXISTS tab_boolean(col1 boolean,col2 boolean);
CREATE TABLE
hrdb=# --插入布尔类型的状态值,状态值可以是以下任意一种
hrdb=# INSERT INTO tab_boolean VALUES(TRUE,FALSE);--规范用法
INSERT 0 1
hrdb=# INSERT INTO tab_boolean VALUES('true','false');
INSERT 0 1
hrdb=# INSERT INTO tab_boolean VALUES('True','False');
INSERT 0 1
hrdb=# INSERT INTO tab_boolean VALUES('TRUE','FALSE');
INSERT 0 1
hrdb=# INSERT INTO tab_boolean VALUES('1','0');
INSERT 0 1
hrdb=# INSERT INTO tab_boolean VALUES('on','off');
INSERT 0 1
hrdb=# INSERT INTO tab_boolean VALUES('ON','OFF');
INSERT 0 1
hrdb=# INSERT INTO tab_boolean VALUES('y','n');
INSERT 0 1
hrdb=# INSERT INTO tab_boolean VALUES('Y','N');
INSERT 0 1
hrdb=# INSERT INTO tab_boolean VALUES('yes','no');
INSERT 0 1
hrdb=# INSERT INTO tab_boolean VALUES('Yes','No');
INSERT 0 1
hrdb=# INSERT INTO tab_boolean VALUES('YES','NO');
INSERT 0 1
hrdb=# SELECT * FROM tab_boolean ;
col1 | col2
------+------
t | f
t | f
t | f
t | f
t | f
t | f
t | f
t | f
t | f
t | f
t | f
t | f
(12 rows)
boolean类型被广泛地使用在业务环境中,例如手机开关机,1表示开机,0表示关机或不在服务区。手机APP登录登出,1表示登录,0表示登出,微信登陆状态,1表示登录成功,0表示登录失败(可能由于网络或者密码错误导致)等等,此处不再一一举例。
四 字符类型
SQL定义了两种主要的字符类型:character varying(n) 和 character(n)。该处的n是一个正数。这两种字符类型都可以存储n(非字节)个长度的字符串。如果存储的字符长度超过了字符类型约束的长度会引起错误,除非多出的字符是空格。
| 名称 | 描述 | 存储空间 |
|---|---|---|
| CHAR(n)CHARACTER(n) | 定长字符串,不足补空格。n是指字符长度,如不带精度n,默认精度为1。 | 最大为10MB。 |
| VARCHAR(n)CHARACTER VARYING(n) | 变长字符串。n是指字符长度。 | 最大为10MB。 |
| TEXT | 变长字符串。 | 最大为1G-8023B(即1073733621B)。 |
注意,除了每列的大小限制以外,每个元组的总大小也不可超过1G-8023B(即1073733621B)。
在PostgreSQL中,除了以上的字符数据类型外,还有两种特殊的字符类型如下:
| 名称 | 描述 | 存储空间 |
|---|---|---|
| name | 用于对象名的内部类型。 | 64字节 |
| “char” | 单字节内部类型。 | 1字节 |
示例:
hrdb=# --创建字符类型表
hrdb=# CREATE TABLE IF NOT EXISTS tab_chartype(
hrdb(# col1 char(15),
hrdb(# col2 varchar(15),
hrdb(# col3 text,
hrdb(# col4 name,
hrdb(# col5 "char" );
CREATE TABLE
hrdb=# --字段注释
hrdb=# COMMENT ON COLUMN tab_chartype.col1 IS '表示定长为15的字符串';
COMMENT
hrdb=# COMMENT ON COLUMN tab_chartype.col2 IS '表示变长为15的字符串';
COMMENT
hrdb=# COMMENT ON COLUMN tab_chartype.col3 IS '表示变长字符串,为varchar的扩展字符串';
COMMENT
hrdb=# COMMENT ON COLUMN tab_chartype.col4 IS '用于对象名的内部类型';
COMMENT
hrdb=# COMMENT ON COLUMN tab_chartype.col5 IS '表示单字节类型';
COMMENT
hrdb=# --插入数据
hrdb=# INSERT INTO tab_chartype
hrdb-# VALUES('sungsasong','sungsasong','sungsasong','tab_chartype','s');
INSERT 0 1
hrdb=# --插入包含空格的数据
hrdb=# INSERT INTO tab_chartype
hrdb-# VALUES('sungsa song','sung sas ong','sung sa song ','tab_chartype','s');
INSERT 0 1
hrdb=# --计算不同数据类型存储的字符串的长度
hrdb=# SELECT char_length(col1),char_length(col2),char_length(col3),char_length(col4),char_length(col5)
hrdb-# FROM tab_chartype ;
char_length | char_length | char_length | char_length | char_length
-------------+-------------+-------------+-------------+-------------
10 | 10 | 10 | 12 | 1
11 | 12 | 13 | 12 | 1
温馨提示:
在上面示例中,虽然统计的col1的定长为15的字符存储的字符长度为10个和11个,但是实际上,在存储中col1列占用的长度为15个。并且,在计算长度的时候,空格也被当作一个字符来对待。
五 二进制数据类型
在PostgreSQL中,二进制数据类型有两种,一种为 bytea hex格式,一种为 bytea escape格式。
| 名称 | 描述 | 存储空间 |
|---|---|---|
| BYTEA | 变长的二进制字符串 | 4字节加上实际的二进制字符串。最大为1G-8203字节。 |
注意:除了每列的大小限制以外,每个元组的总大小也不可超过1G-8203字节。示例
hrdb=# --创建两种bytea格式的表
hrdb=# CREATE TABLE IF NOT EXISTS tab_bytea(col1 bytea,col2 bytea);
CREATE TABLE
hrdb=# --字段注释
hrdb=# COMMENT ON COLUMN tab_bytea.col1 IS 'bytea hex 格式的二进制串';
COMMENT
hrdb=# COMMENT ON COLUMN tab_bytea.col2 IS 'bytea escape 格式的二进制串';
COMMENT
hrdb=# --插入数据,第一个值代表单引号,输出16进制的值为\x27,第二个为转义16进制的值f
hrdb=# INSERT INTO tab_bytea
hrdb-# VALUES('\047',E'\xF');
INSERT 0 1
hrdb=# --插入数据,第一个值代表反斜杠,输出16禁止的值为\x5c,第二个值为转义16进制的值fc
hrdb=# INSERT INTO tab_bytea
hrdb-# VALUES('\134',E'\\xFC');
INSERT 0 1
hrdb=# --查看结果
hrdb=# SELECT * FROM tab_bytea;
col1 | col2
------+------
\x27 | \x0f
\x5c | \xfc
注意:
实际上bytea多个十六进制值使用E'\xFC' 类似于Oracle中的rawtohex函数。只不过Oracle中的rawtohex函数转换后的值为大写十六进制字符串。实际上如果要在上表中的col2中插入E'\xFG'时,会提示G不是一个有效的十六进制字符。
同时需要注意的是,如果使用E'\xF'只包含单个十六进制字符时,使用一个反斜杠,如果有多个十六进制字符,需要两个反斜杠,如E'\xFE'。
如下:此处的hextoraw函数为我自定义实现的一个UDF函数。
六 日期时间数据类型
PostgreSQL支持丰富的日期时间数据类型如下表:
| 名称 | 描述 | 存储空间 |
|---|---|---|
| DATE | 日期和时间 | 4字节(实际存储空间大小为8字节) |
| TIME [§] [WITHOUT TIME ZONE] | 只用于一日内时间。p表示小数点后的精度,取值范围为0-6。 | 8字节 |
| TIME [§] [WITH TIME ZONE] | 只用于一日内时间,带时区。p表示小数点后的精度,取值范围为0-6。 | 12字节 |
| TIMESTAMP[§] [WITHOUT TIME ZONE] | 日期和时间。p表示小数点后的精度,取值范围为0-6。 | 8字节 |
| TIMESTAMP[§][WITH TIME ZONE] | 日期和时间,带时区。TIMESTAMP的别名为TIMESTAMPTZ。p表示小数点后的精度,取值范围为0-6。 | 8字节 |
| reltime | 相对时间间隔。格式为:X years X mons X days XX:XX:XX。 | 4字节 |
6.1日期输入
日期和时间的输入可以是任何合理的格式,包括ISO-8601格式、SQL-兼容格式、传统POSTGRES格式或者其它的形式。系统支持按照日、月、年的顺序自定义日期输入。如果把DateStyle参数设置为MDY就按照“月-日-年”解析,设置为DMY就按照“日-月-年”解析,设置为YMD就按照“年-月-日”解析。
日期的文本输入需要加单引号包围,语法如下:
type [ ( p ) ] 'value'
可选的精度声明中的p是一个整数,表示在秒域中小数部分的位数。
示例:
hrdb=> --创建日期输入表
hrdb=> CREATE TABLE tab_datetype(col1 date);
CREATE TABLE
hrdb=> --字段注释
hrdb=> COMMENT ON COLUMN tab_datetype.col1 IS '日期类型,默认遵循datestyle风格(MDY)';
COMMENT
hrdb=> --插入数据
hrdb=> INSERT INTO tab_datetype VALUES(date '04-26-2020');
INSERT 0 1
hrdb=> --在MDY风格下,也支持YMD的输入方式,但是不支持DMY或者其它格式的输入,如下会报错
hrdb=> INSERT INTO tab_datetype VALUES(date '22-04-2020');
ERROR: date/time field value out of range: "22-04-2020"
LINE 1: INSERT INTO tab_datetype VALUES(date '22-04-2020');
^
HINT: Perhaps you need a different "datestyle" setting.
hrdb=> --解决办法,修改datestyle的格式
hrdb=> --查看当前数据库的datestyle的格式
hrdb=> show datestyle;
DateStyle
-----------
ISO, MDY
(1 row)
hrdb=> --会话级别修改datestyle格式
hrdb=> SET datestyle = 'DMY';
SET
hrdb=> --再次插入 22-04-2020
hrdb=> INSERT INTO tab_datetype VALUES(date '22-04-2020');
INSERT 0 1
hrdb=> --查询数据
hrdb=> SELECT * FROM tab_datetype ;
col1
------------
2020-04-26
2020-04-22
6.2时间输入
时间类型包括 time [ (p) ] without time zone 和time [ (p) ] with time zone。 如果只写time等效于time without time zone。即不带时区的时间格式 如果在time without time zone类型的输入中声明了时区,则会忽略这个时区。 示例: hrdb=> --不带时区的时间 hrdb=> SELECT time '13:22:25'; time ---------- 13:22:25 (1 row) hrdb=> SELECT time without time zone '20:20:18'; time ---------- 20:20:18 (1 row) hrdb=> SELECT time with time zone '18:20:20'; timetz ------------- 18:20:20+08 (1 row)
6.3 特殊时间类型
特殊时间类型以reltime表示,表示真实的时间计算值,如100将会使用00:01:40来表示。
示例:
hrdb=> --创建reltime时间数据类型表
hrdb=> CREATE TABLE tab_reltime(col1 varchar,col2 reltime);
CREATE TABLE
hrdb=> --字段注释
hrdb=> COMMENT ON COLUMN tab_reltime.col1 IS '原始时间文本时间';
COMMENT
hrdb=> COMMENT ON COLUMN tab_reltime.col2 IS 'reltime表示的时间以实际时间计算得到显示结果';
COMMENT
hrdb=> --插入数据
hrdb=> INSERT INTO tab_reltime VALUES('125','125');
INSERT 0 1
hrdb=> INSERT INTO tab_reltime VALUES('10 DAYS','10 DAYS');
INSERT 0 1
hrdb=> INSERT INTO tab_reltime VALUES('420 DAYS 12:00:23','420 DAYS 12:00:23');
INSERT 0 1
hrdb=> --查询数据
hrdb=> SELECT * FROM tab_reltime;
col1 | col2
-------------------+-------------------------------
125 | 00:02:05
10 DAYS | 10 days
420 DAYS 12:00:23 | 1 year 1 mon 25 days 06:00:23
温馨提示:
对于 reltime 时间的输入,需要使用文本类型的输入,也就是说使用单引号引起来。
6.4 其它时间类型
其它时间类型包含时间戳及间隔时间数据类型,示例如下:
示例:
hrdb=> --创建时间戳和间隔时间表
hrdb=> CREATE TABLE tab_timestamp_interval(col1 timestamp with time zone,col2 timestamp without time zone,col3 interval day to second);
CREATE TABLE
hrdb=> --字段注释
hrdb=> COMMENT ON COLUMN tab_timestamp_interval.col1 IS '带时区的时间戳';
COMMENT
hrdb=> COMMENT ON COLUMN tab_timestamp_interval.col2 IS '不带时区的时间戳';
COMMENT
hrdb=> COMMENT ON COLUMN tab_timestamp_interval.col1 IS '间隔时间类型';
COMMENT
hrdb=> --插入数据
hrdb=> INSERT INTO tab_timestamp_interval
hrdb-> VALUES('2020-04-26 13:20:34.234322 CST',
hrdb(> '2020-04-08 14:40:12.234231+08',
hrdb(> '165');
INSERT 0 1
hrdb=> INSERT INTO tab_timestamp_interval
hrdb-> VALUES('2020-04-25 14:56:34.223421',
hrdb(> '2020-04-09 18:54:12.645643 CST',
hrdb(> '10 YEAR 3 MONTH 25 DAYS 14 HOUR 32 MINUTE 19 SECOND');
INSERT 0 1
hrdb=> --查询数据
hrdb=> SELECT * FROM tab_timestamp_interval;
col1 | col2 | col3
-------------------------------+----------------------------+----------------------------------
2020-04-27 03:20:34.234322+08 | 2020-04-08 14:40:12.234231 | 00:02:45
2020-04-25 14:56:34.223421+08 | 2020-04-09 18:54:12.645643 | 10 years 3 mons 25 days 14:32:19
时间数据类型在业务应用中使用非常广泛,如手机APP登录时间,登出时间,金融业务交易时间等等.
七 网络地址类型
PostgreSQL也提供网络地址类型,以用于存储两大IP家族(IPv4 IPv6地址)地址和MAC地址的数据类型。
| 名称 | 存储空间 | 描述 |
|---|---|---|
| cidr | 7或19字节 | IPv4或IPv6网络 |
| inet | 7或19字节 | IPv4或IPv6主机和网络 |
| macaddr | 6字节 | MAC地址 |
cidr(无类别域间路由,Classless Inter-Domain Routing)类型,保存一个IPv4或IPv6网络地址。声明网络格式为address/y,address表示IPv4或者IPv6地址,y表示子网掩码的二进制位数。如果省略y,则掩码部分使用已有类别的网络编号系统进行计算,但要求输入的数据已经包括了确定掩码所需的所有字节。
inet类型在一个数据区域内保存主机的IPv4或IPv6地址,以及一个可选子网。主机地址中网络地址的位数表示子网(“子网掩码”)。如果子网掩码是32并且地址是IPv4,则这个值不表示任何子网,只表示一台主机。在IPv6里,地址长度是128位,因此128位表示唯一的主机地址。
该类型的输入格式是address/y,address表示IPv4或者IPv6地址,y是子网掩码的二进制位数。如果省略/y,则子网掩码对IPv4是32,对IPv6是128,所以该值表示只有一台主机。如果该值表示只有一台主机,/y将不会显示。
inet和cidr类型之间的基本区别是inet接受子网掩码,而cidr不接受。
macaddr类型存储MAC地址,也就是以太网卡硬件地址(尽管MAC地址还用于其它用途)。
示例:
hrdb=> --创建IP地址及MAC地址表
hrdb=> CREATE TABLE tab_icm(col1 cidr,col2 inet,col3 macaddr);
CREATE TABLE
hrdb=> --字段注释
hrdb=> COMMENT ON COLUMN tab_icm.col1 IS '存储IPv4或IPv6网络地址类型';
COMMENT
hrdb=> COMMENT ON COLUMN tab_icm.col2 IS '存储IPv4或IPv6网络地址类型及子网';
COMMENT
hrdb=> COMMENT ON COLUMN tab_icm.col3 IS '存储设备MAC地址';
COMMENT
hrdb=> --插入数据
hrdb=> INSERT INTO tab_icm VALUES('10.10.20.10/32','10.10.20.10','00-50-56-C0-00-08');
INSERT 0 1
hrdb=> INSERT INTO tab_icm VALUES('10.10.20/24','10.10.20.10','00-50-56-C0-00-08');
INSERT 0 1
hrdb=> INSERT INTO tab_icm VALUES('10.10/16','10.10.20.10','00-50-56-C0-00-08');
INSERT 0 1
hrdb=> INSERT INTO tab_icm VALUES('10/8','10.10.20.10','00-50-56-C0-00-08');
INSERT 0 1
hrdb=> INSERT INTO tab_icm VALUES('fe80::81a7:c17c:788c:7723/128','fe80::81a7:c17c:788c:7723','00-50-56-C0-00-01');
INSERT 0 1
hrdb=> --查询数据
SELECT * FROM tab_icm;
col1 | col2 | col3
-------------------------------+---------------------------+-------------------
10.10.20.10/32 | 10.10.20.10 | 00:50:56:c0:00:08
10.10.20.0/24 | 10.10.20.10 | 00:50:56:c0:00:08
10.10.0.0/16 | 10.10.20.10 | 00:50:56:c0:00:08
10.0.0.0/8 | 10.10.20.10 | 00:50:56:c0:00:08
fe80::81a7:c17c:788c:7723/128 | fe80::81a7:c17c:788c:7723 | 00:50:56:c0:00:01
(5 rows)
八 几何数据类型
PostgreSQL支持集合数据类型,用于存储GIS(地理信息系统)环境中的几何数据,用于地图测绘,城市交通轨迹,地图圈图等场景。
PostgreSQL支持以下几何数据类型:
点
线(射线)
线段
矩形
路径(包含开放路径【开放路径类似多边形】和闭合路径)
多边形
圆
对于以上几何类型而言,点是其它几何类型的基础。
| 名称 | 存储空间 | 说明 | 表现形式 |
|---|---|---|---|
| point | 16字节 | 平面中的点 | (x,y) |
| lseg | 32字节 | (有限)线段 | ((x1,y1),(x2,y2)) |
| box | 32字节 | 矩形 | ((x1,y1),(x2,y2)) |
| path | 16+16n字节 | 闭合路径(与多边形类似) | ((x1,y1),…) |
| path | 16+16n字节 | 开放路径 | [(x1,y1),…] |
| polygon | 40+16n字节 | 多边形(与闭合路径相似) | ((x1,y1),…) |
| circle | 24字节 | 圆 | <(x,y),r> (圆心和半径) |
对于所有的几何数据类型,都是使用二维坐标上面的横坐标和纵坐标来实现的。计算也是在二维坐标中进行的。
示例:
hrdb=> --创建几何数据类型表
hrdb=> CREATE TABLE tab_geometric(col1 point,col2 lseg,col3 box,col4 path,col5 path,col6 polygon,col7 circle);
CREATE TABLE
hrdb=> --字段注释
hrdb=> COMMENT ON COLUMN tab_geometric.col1 IS '二维几何的基本构造点(x,y)';
COMMENT
hrdb=> COMMENT ON COLUMN tab_geometric.col2 IS '线段((x1,y1),(x2,y2))';
COMMENT
hrdb=> COMMENT ON COLUMN tab_geometric.col3 IS '矩形((x1,y1),(x1,y2),(x2,y1),(x2,y1)),';
COMMENT
hrdb=> COMMENT ON COLUMN tab_geometric.col4 IS '开放路径((x1,y1),(x2,y2),(x3,y3),...)';
COMMENT
hrdb=> drop table tab_geometric ;
DROP TABLE
hrdb=> --创建几何数据类型表
hrdb=> CREATE TABLE tab_geometric(col1 point,col2 lseg,col3 box,col4 path,col5 path,col6 polygon,col7 circle);
CREATE TABLE
hrdb=> --字段注释
hrdb=> COMMENT ON COLUMN tab_geometric.col1 IS '二维几何的基本构造点(x,y)';
COMMENT
hrdb=> COMMENT ON COLUMN tab_geometric.col2 IS '线段[(x1,y1),(x2,y2)]';
COMMENT
hrdb=> COMMENT ON COLUMN tab_geometric.col3 IS '矩形((x1,y1),(x1,y2)),';
COMMENT
hrdb=> COMMENT ON COLUMN tab_geometric.col4 IS '开放路径[(x1,y1),(x2,y2),(x3,y3),...]';
COMMENT
hrdb=> COMMENT ON COLUMN tab_geometric.col5 IS '闭合路径[(x1,y1),(x2,y2),(x3,y3),...,(xn,yn)]';
COMMENT
hrdb=> COMMENT ON COLUMN tab_geometric.col6 IS '多边形,相当于闭合路径((x1,y1),(x2,y2),(x3,y3),...,(xn,yn)';
COMMENT
hrdb=> COMMENT ON COLUMN tab_geometric.col7 IS '一组坐标点作为圆心和半径r构成<(x,y),r>';
COMMENT
hrdb=> --插入数据
hrdb=> INSERT INTO tab_geometric
hrdb-> VALUES('(1,2)',
hrdb(> '[(1,2),(2,3)]',
hrdb(> '((1,2),(1,3))',
hrdb(> '[(1,2),(2,3),(2,4),(1,3),(0,2)]',
hrdb(> '[(1,2),(2,3),(3,4)]',
hrdb(> '((1,2),(2,3),(2,4),(1,3),(0,2))',
hrdb(> '<(2,3),3>');
INSERT 0 1
hrdb=> --查询数据
hrdb=> SELECT * FROM tab_geometric;
col1 | col2 | col3 | col4 | col5 | col6 | col7
-------+---------------+-------------+---------------------------------+---------------------+---------------------------------+-----------
(1,2) | [(1,2),(2,3)] | (1,3),(1,2) | [(1,2),(2,3),(2,4),(1,3),(0,2)] | [(1,2),(2,3),(3,4)] | ((1,2),(2,3),(2,4),(1,3),(0,2)) | <(2,3),3>
九 JSON数据类型
JSON数据类型可以用来存储JSON(JavaScript Object Notation)数据。数据可以存储为text,但是JSON数据类型更有利于检查每个存储的数值是可用的JSON值。
在 PostgreSQL中,JSON数据类型有两种,原生JSON和JSONB。最主要的区别就是效率不同。JSON 数据类型对于输入文本进行复制,因此在解析时需要进行转换,输入速度块。而JSONB是对输入文本进行分解并以二进制存储,因此在解析时不需要进行转换,处理速度块,但是输入速度相对会慢。除此之外,JSONB数据类型还支持索引。
示例:
hrdb=> --创建JSON数据类型表
hrdb=> CREATE TABLE tab_json(col1 json,col2 jsonb);
CREATE TABLE
hrdb=> --字段注释
hrdb=> COMMENT ON COLUMN tab_json.col1 IS '存储json输入文本';
COMMENT
hrdb=> COMMENT ON COLUMN tab_json.col1 IS '存储json转换后的二进制文本';
COMMENT
hrdb=> --插入数据
hrdb=> --插入数据
hrdb=> INSERT INTO tab_json
hrdb-> VALUES('{"江苏省":"南京市","甘肃省":"兰州市","北京市":"北京市"}',
hrdb(> '{"湖北省":"武汉市","四川省":"成都市","陕西省":"西安市"}');
INSERT 0 1
hrdb=> --给col1创建索引,将会不被支持。col2支持索引
hrdb=> CREATE INDEX idx_col1 ON tab_json USING GIN(col1);
ERROR: data type json has no default operator class for access method "gin"
HINT: You must specify an operator class for the index or define a default operator class for the data type.
hrdb=> CREATE INDEX idx_col2 ON tab_json USING GIN(col2);
CREATE INDEX
hrdb=> --查询数据
hrdb=> SELECT * FROM tab_json;
col1 | col2
---------------------------------------------------------+--------------------------------------------------------------
{"江苏省":"南京市","甘肃省":"兰州市","北京市":"北京市"} | {"四川省": "成都市", "湖北省": "武汉市", "陕西省": "西安市"}
温馨提示:
使用jsonb类型,可以使用PL/PYTHON映射为Python中表示的字典,列表等。
十 数组数据类型
ostgreSQL支持数组数据类型,同时支持多维数组。数组最大的优点就是按照数组下标访问,此时下标相当于一个索引,处理速度快。但是同时数组也有劣势,比如在删除或者添加数组元素需要对数组中的元素进行向前或者向后移动,这样导致删除或者添加数组元组时比较慢。
示例:
hrdb=> --创建数组表
hrdb=> CREATE TABLE tab_array(col1 text[],col2 integer[][],col3 integer ARRAY[3]);
CREATE TABLE
hrdb=> --字段注释
hrdb=> COMMENT ON COLUMN tab_array.col1 IS '文本类型一维数组';
COMMENT
hrdb=> COMMENT ON COLUMN tab_array.col2 IS '整型类型二维数组';
COMMENT
hrdb=> COMMENT ON COLUMN tab_array.col3 IS '声明长度为3的数组';
COMMENT
hrdb=> --插入数据
hrdb=> INSERT INTO tab_array
hrdb-> VALUES('{"江苏省","甘肃省","北京市"}',
hrdb(> '{1,2,3,4,5}',
hrdb(> '{21,22,31}');
INSERT 0 1
hrdb=> INSERT INTO tab_array
hrdb-> VALUES('{"天津市","湖北省","陕西市"}',
hrdb(> '{5,4,3,2,1}',
hrdb(> '{21,22,31,44}');
INSERT 0 1
hrdb=> --查询数据
hrdb=> SELECT * FROM tab_array;
col1 | col2 | col3
------------------------+-------------+---------------
{江苏省,甘肃省,北京市} | {1,2,3,4,5} | {21,22,31}
{天津市,湖北省,陕西市} | {5,4,3,2,1} | {21,22,31,44}
(2 rows)
hrdb=> --访问指定列中某个数组的元素
hrdb=> SELECT col1[1],col2[3],col3[4] FROM tab_array;
col1 | col2 | col3
--------+------+------
江苏省 | 3 |
天津市 | 3 | 44
通过上述示例,可以发现,在PostgreSQL中,虽然声明了数组的长度,但是PostgreSQL对于数组的长度不会做任何限制。
同时访问数组元素从下标1开始,并且在PostgreSQL中并不会出现数组越界异常,如果数组的下标访问超过元素的长度,那么PostgreSQL便会返回一行空值。
以上就是常用数据类型介绍。但是在PostgreSQL中,除了上述数据类型外,还有其它的数据类型,比如XML数据类型,文本搜索数据类型,UUID数据类型,复合数据类型,范围类型,伪类型如any,anyelement,internal等等,在此不做一一介绍。
版权声明
本文仅代表作者观点,不代表本站立场。
本文系作者授权发表,未经许可,不得转载。
本文地址:/shujuku/PostgreSQL/107003.html