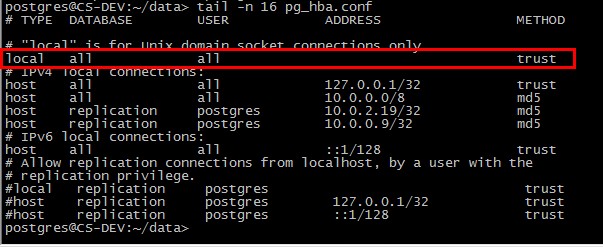
PostgreSQL 实现distinct关键字给单独的几列去重
PostgreSQL去重问题一直困扰着我,distinct和group by远不如MySQL用起来随便,但是如果掌握了规律,还是和MySQL差不多的
主要介绍的是distinct关键字

select distinct id,name,sex,age from student
假如有一张student表,字段如上图,我查询student表中所有信息用distinct去重(上面的SQL语句),pgsql就会根据所有的字段通过算法取得重复行的第一行,但是很明显,ID这个字段我在设计的时候不会让它重复,所以相当于没有去重
我想只根据name和age去重怎么办?
可以这么写
select distinct on (name,age) id,name,sex,age from student
这样就会只根据name和age去重了
总结一下:
distinct on (),括号里面的内容是要去重的列,括号外面的内容是你要查询展示的列,两者没有关系,你可以根据某些列去重不必将他们查询出来,最后这个举一个例子就是:
我要查询name和age,根据name和sex去重:
select distinct on (name,sex) name,age from student
补充:PostgreSQL按照某一字段去重,并显示其他字段信息
以前遇到去重的地方更多的是MySQL去重后统计,比如select count(distinct 字段) from 表,后来临时遇到用Postgresql查询全部信息,但要对某个字段去重,查资料发现select * from table group by 要去重的字段,在MySQL上可以用,就搬到Postgresql试一下发现不行,又Google一番,终于找到一种方案:select distinct on(字段) * from 表,就可以了。
如下图:

对name字段去重后再查询全部字段:

以上为个人经验,希望能给大家一个参考,也希望大家多多支持潘少俊衡。如有错误或未考虑完全的地方,望不吝赐教。
版权声明
本文仅代表作者观点,不代表本站立场。
本文系作者授权发表,未经许可,不得转载。
本文地址:/shujuku/PostgreSQL/106659.html