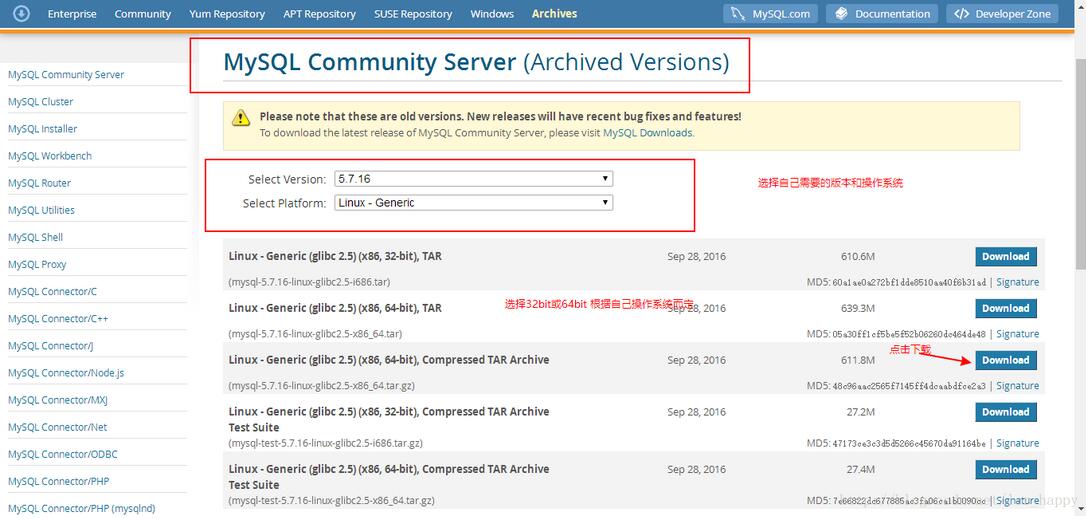
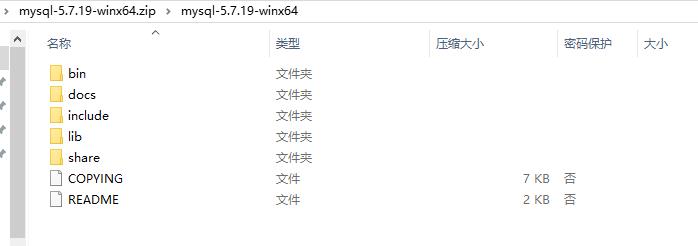
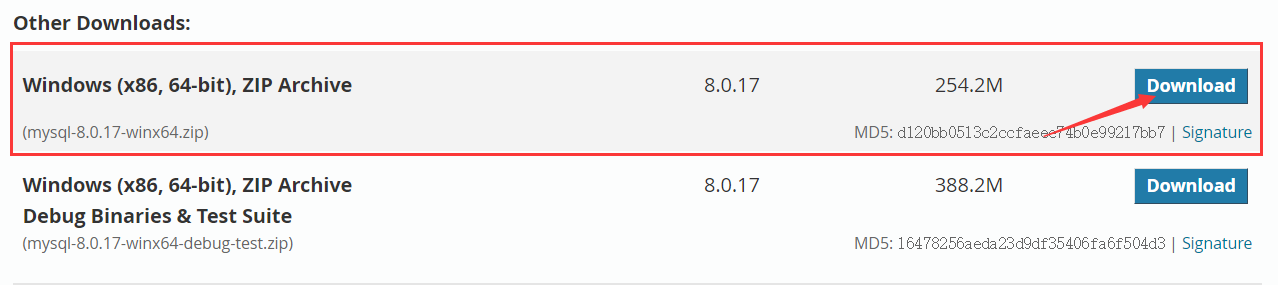
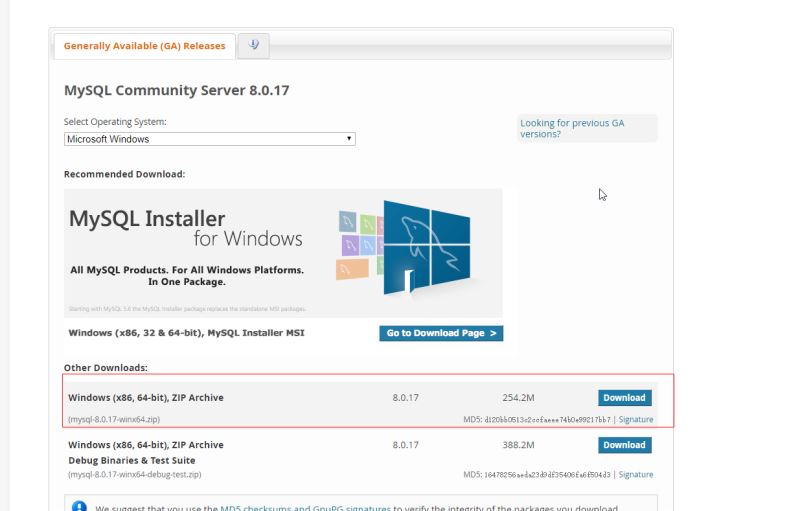
深入浅出的学习Mysql
前言
数据库一直是笔者比较薄弱的地方,结合自己的使用经验(python+sqlalchemy)等做个记录,笔者比较喜欢使用ORM,一直感觉拼sql是一件比较痛苦的事情(主要是不擅长sql),以前维护项的目中也遇到过一些数据库的坑,比如编码问题,浮点数精度损失等,防止以后重复踩坑。
1章:使用帮助
使用mysql内置的帮助命令
msyql> ? data types: 查看数据类型mysql> ? intmysql> ? create table
2章:表类型(存储引擎)的选择
最常用的两种引擎:
1、Myisam是Mysql的默认存储引擎,当create创建新表时,未指定新表的存储引擎时,默认使用Myisam。 每个MyISAM 在磁盘上存储成三个文件。文件名都和表名相同,扩展名分别是 .frm (存储表定义) 、.MYD (MYData,存储数据)、.MYI (MYIndex,存储索引)。数据文件和 索引文件可以放置在不同的目录,平均分布io,获得更快的速度。
2、InnoDB 存储引擎提供了具有提交、回滚和崩溃恢复能力的事务安全。但是对比 Myisam 的存储引擎,InnoDB 写的处理效率差一些并且会占用更多的磁盘空间以保留数据和索引。
常用环境:
1、MyISAM: 默认的 MySQL 插件式存储引擎, 它是在 Web、 数据仓储和其他应用环境下最常
使用的存储引擎之一
2、InnoDB:用于事务处理应用程序,具有众多特性,包括 ACID 事务支持。
3章:选择合适的数据类型
首先选择合适的存储引擎,根据指定的存储引擎确定合适的数据类型。
- MyISAM: 最好使用固定长度的数据列代替可变长度的数据列。
- InnoDB: 建议使用varchar
需要注意的一些数据类型:
1、char与varchar: 保存和检索方式不同,最大长度和是否尾部空格被保留也不同。char固定长度,长度不够用空格填充,获取时如果没有设置 PAD_CHAR_TO_FULL_LENGTH默认去除尾部空格。
varchar变长字符串,检索时尾部空格会被保留。注意查询时候不区分大小写,如果用sqlalchemy区分大小写不要用func.binary函数。
2、text和blob: text和blob执行大量的更新或者删除的时候会留下很大『空洞』,建议定期用OPTIMIZE TABLE功能对这类表碎片整理。避免检索大型的blob或text值 。把text和blob列分离到单独的表中。
3、浮点数float与定点数decimal:
注意几个点:
1.浮点数虽然能表示更大的数据范围,但是有误差问题。
2.对货币等精度敏感的问题,应使用定点数存储。之前项目踩过坑,结果不得不用放大和缩小倍数的方法解决,比较ugly。
3.编程如果遇到浮点数,注意误差问题,尽量避免浮点数比较(比较浮点数需要作差小于一个特定精度),python3.5中可以这么比较:float_eq = partial(math.isclose, rel_tol=1e-09, abs_tol=0.0)
4.注意浮点数中一些特殊值的处理。
4章:字符集
一开始要选择合适的字符集,否则后期更换代价很高。python2中字符集就是个老大难问题,困然很多新手。之前维护过的项目使用了msyql默认的latin1字符集,导致每次写入的时候都要对字符串手动encode成utf8。最近用python3.5+flask做项目直接使用utf8,再也没碰到过编码问题:
- 创建数据库使用utf8,CREATE DATABASE IF NOT EXISTS my_db default charset utf8 COLLATE utf8_general_ci;
- sqlalchemy连接url使用mysql://root:root@127.0.0.1:3306/my_db?charset=utf8。不用担心乱码问题了
5章:索引的设计和使用
所有mysql列类型都可以被索引,对相关列使用索引是提高select操作性能的最佳途径。索引设计的原则:
1.搜索的索引列,不一定是所要选择的列。最适合的索引的列是出现在where子句中的列,或连接子句中指定的列,而不是出现在select关键字之后的选择列表中的列。
2.使用唯一索引。对于唯一值的列,索引效果较好,而有多个重复值的列,索引效果差。
3.使用短索引。如果对字符串列进行索引,应指定一个前缀长度,只要有可能就应该这样做。
4.利用最左前缀。在创建一个n列索引时,实际上创建了mysql可利用的n个索引。多列索引可以起到几个索引的作用,因为可利用索引中的最左边的列集来匹配行,这样的列集成为最左前缀。
5.不要过度索引。索引会浪费磁盘空间,降低写入性能。
6.考虑在列上进行的比较类型。
6章:锁机制和事务控制
InnoDB引擎提提供行级锁,支持共享锁和排他锁两种锁定模式,以及四种不同的隔离级别。mysql通过AUTOCOMIT, START TRANSACTIONS, COMMIT和ROLLBACK等语句支持本地事务。
7章:SQL中的安全问题
SQL注入:利用某些数据库的外部接口把用户数据插入到实际的数据库操作语音(sql)中,从而达到入侵数据库甚至操作系统的目的。产生原因主要是因为程序堆用户输入的数据没有进行严格的过滤,导致非法数据库查询语句的执行,防范措施:
prepareStatement = Bind-variable,不要使用拼接的sql- 使用应用程序提供的转换函数
- 自定义函数校验(表单校验等)
8章:SQL Mode及相关问题
更改默认的mysql执行模式,比如严格模式下列的插入或者更新不正确时mysql会给出错误,并放弃操作。set session sql_mode='STRICT_TRANS_TABLES'。设置sql_mode需要应用人员权衡各种得失,做一个合适的选择。
9章:常用SQL技巧
- 检索包含最大/最小值的行:
MAX([DISTINCE] expr), MIN([DISTINCE] expr) - 巧用
rand()/rand(n)提取随机行 - 利用
group by和with rollup子句做统计 - 用
bit group functions做统计
10章:其他需要注意的问题
数据库名、表名大小写问题:不同平台和系统,是否区分大小写是不同的。建议就是始终统一使用小写名。
使用外键需要注意的地方:mysql中InnoDB支持对外部关键字约束条件的检查。
11章:SQL优化
优化SQL的一般步骤:
1.使用show status和应用特点了解各种SQL的执行频率,了解各种SQL大致的执行比例。比如InnoDB的的参数Innode_rows_read查询返回的行数,Innodb_rows_inserted执行insert插入的行数,Innodb_rows_updated更新的行数。还有一下几个参数:Connections试图连接mysql服务器嗯出书,Uptime服务器的工作时间,Slow_queries慢查询的次数。
2.定位执行效率低的SQL语句。两种方式:一种是通过慢查询日志定位执行效率低的语句,使用—log-slow-queries[=file_name]选项启动时,mysqld写一个包含所有执行时间超过long_query_time秒的SQL语句的日志文件。另一种是show processlist查看当前mysql在进行的线程,包括线程的状态,所否锁表等,可以实时查看SQL执行情况,同时对一些锁表操作进行优化。
3.通过EXPLAIN分析低效SQL的执行计划:explain可以知道什么时候必须为表假如索引以得到一个使用索引来寻找记录的更快的SELECT,以下是EXPLAIN执行后得到的结果说明:
- select_type: select类型
- table: 输出结果集的表
- type: 表示表的连接类型。当表中仅有一行是type的值为system是最佳的连接类型;当select操作中使用索引进行表连接时type值为ref;当select的表连接没有使用索引时,经常看到type的值为ALL,表示对该表进行了全表扫描,这时需要考虑通过创建索引提高表连接效率。
- possible_keys: 表示查询时,可以使用的索引列。
- key: 表示使用的索引
- key_len: 索引长度
- rows: 扫描范围
- Extra: 执行情况的说明和描述
4.确定问题,并采取相应优化措施。
索引问题
- 索引的存储分类: myisam表的数据文件和索引文件自动分开,innodb的数据和索引放在同一个表空间里面。myisam和innodb的索引存储类型都是btree
- Mysql如何使用索引: 索引用于快速查找某个列中特定值的行。查询要使用索引最主要的条件是要在查询条件中使用索引关键子,如果是多列索引,那么只有查询条件中使用了多列关键字最左边的前缀时,才可以使用索引,否则将不能使用索引。
- 查看索引的使用情况:Handler_read_key的值代表一个行被索引次数,值低表示索引不被经常使用。Handler_read_rnd_next值高意味着查询运行低效,应该建立索引补救。
show status like 'Handler_read%';
两个简单实用的优化方法
- 定期分析表:ANALYZE TABLE, CHECK TABLE, CHECKSUM TABLE
- 使用OPTIMIZE table;
从客户端(代码端)角度优化
- 使用持久的连接数据库以避免连接开销。代码中我们一般使用连接池
- 检查所有的插叙确实使用了必要的索引。
- 避免在频繁更新的表上执行复杂的select查询,以避免与锁表有关的由于读,写冲突发生的问题。
- 充分利用默认值,只有插入值不同于默认值才明确插入值。减少mysql需要做的语法分析从而提高插入速度。
- 读写分离提高性能
- 表字段尽量不用自增长变量,防止高并发情况下该字段自增影响效率,推荐通过应用实现字段的自增。
12章: 优化数据库对象
优化表的数据类型:PROCEDURE ANALYZE()对当前表类型的判断提出优化建议。实际可以通过统计信息结合应用实际优化。
通过拆分,提高表的访问效率:这里拆分主要是针对Myisam类型的表。
- 纵向拆分:按照应用访问的频度,将表中经常访问的字段和不经常访问的字段拆分成两个表,经常访问的字段尽量是定长的。
- 横向拆分:按照应用情况,有目的地将数据横向拆分成几个表或者通过分区分到多个分区中,这样可以有效避免Myisam表的读取和更新导致的锁问题。
逆规范化:规范化设计强调独立性,数据尽可能少冗余,更多冗余意味着占用更多物理空间,同事也对数据维护和一致性检查带来问题。适当冗余可以减少多表访问,查询效率明显提高,这种情况可以考虑适当通过冗余提高效率。
使用冗余统计表:使用create temporary table做统计分析
选择更合适的表类型:1.如果应用出现比较严重的锁冲突,请考虑是否刻意更改存储引擎到InnoDB,行锁机制可以有效减少锁冲突出现。2.如果应用查询操作很多,且对事务完整性要求不严格,可以考虑使用Myisam。
13章:锁问题
获取锁的等待情况:table_locks_waited和table_locks_immediate状态变量来分析系统上的表锁定争夺。检查Innode_row_lock分析行锁的争夺情况。
14章:优化Mysql Server
查看Mysql Server当前参数
- 查看服务器参数默认值:
mysqld --verbose --help - 查看服务器参数实际值:
shell> mysqladmin variables or mysql> SHOW VARIABLES - 查看服务器运行状态值:
mysqladmin extended-status or mysql>SHOW STATUS
影响Mysql性能的重要参数
- key_buffer_size: 键缓存
- table_cache: 数据库中打开的缓存数量
- innode_buffer_pool_size: 缓存InnoDB数据和索引的内存缓冲区的大小
- innodb_flush_log_at_trx_commit: 推荐设成1,在每个事务提交时,日志缓冲被写到日志文件,对日志文件做到磁盘操作的刷新。
15章:I/O问题
磁盘搜索是巨大的性能瓶颈。
- 使用磁盘阵列或虚拟文件卷分布I/O
- 使用Symbolic Links分布I/O
16章:应用优化
- 使用连接池:建立连接代价比较高,通过建立连接池提高访问性能。
- 减少对Mysql的访问:1.避免对同意数据重复检索。2使用mysql query cache
- 增加cache层
- 负载均衡:1.利用mysql复制分流查询操作。2分布式数据库架构
总结
以上就是关于mysql的相关内容,希望本文的内容对大家学习或者使用mysql能带来一定的帮助,如果有疑问大家可以留言交流。
版权声明
本文仅代表作者观点,不代表本站立场。
本文系作者授权发表,未经许可,不得转载。
本文地址:/shujuku/MySQL/107293.html