MySQL中exists、in及any的基本用法
【1】exists
对外表用loop逐条查询,每次查询都会查看exists的条件语句。
当 exists里的条件语句能够返回记录行时(无论记录行是多少,只要能返回),条件就为真 , 返回当前loop到的这条记录。反之如果exists里的条件语句不能返回记录行,条件为假,则当前loop到的这条记录被丢弃。
exists的条件就像一个boolean条件,当能返回结果集则为1,不能返回结果集则为 0。
语法格式如下:
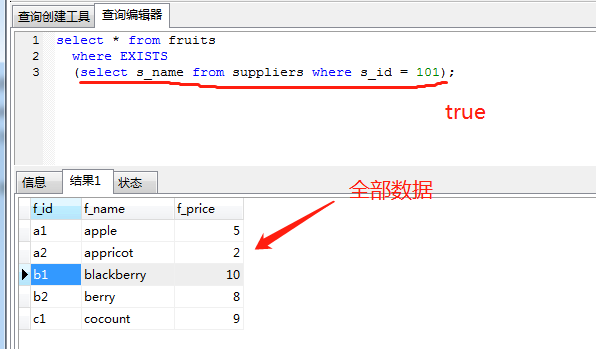
select * from tables_name where [not] exists(select..);
示例如下:
select * from p_user_2 where EXISTS(select * from p_user where id=12)
如果p_user表中有id为12的记录,那么将返回所有p_user_2表中的记录;否则,返回记录为空。
如果是not exists,则与上述相反。
总的来说,如果A表有n条记录,那么exists查询就是将这n条记录逐条取出,然后判断n遍exists条件
【2】in
语法格式如下:
select * from A where column in (select column from B);
需要说明的是,where中,column为A的某一列,in 所对应的子查询语句返回为一列多行结果集。
注意,in所对应的select语句返回的结果一定是一列!可以为多行。
示例如下:
select * from p_user_2 where id [not] in (select id from p_user )
查询id在p_user表id集合的p_user_2的记录。not in则相反。
【3】exists与in的关系
经过sql改变,二者是可以达到同一个目标的:
select * from p_user_2 where id [not] in (select id from p_user ); select * from p_user_2 where [not] EXISTS (select id from p_user where id = p_user_2.id )
那么什么时候用exists 或者in呢?
**如果查询的两个表大小相当,那么用in和exists差别不大。 **
**如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in: **
例如:表A(小表),表B(大表)
① 子查询表为表B:
select * from A where cc in (select cc from B) //效率低,用到了A表上cc列的索引; select * from A where exists(select cc from B where cc=A.cc) //效率高,用到了B表上cc列的索引。
② 子查询表为表A:
select * from B where cc in (select cc from A) //效率高,用到了B表上cc列的索引; select * from B where exists(select cc from A where cc=B.cc) //效率低,用到了A表上cc列的索引。
not in 和not exists如果查询语句使用了not in 那么内外表都进行全表扫描,没有用到索引;而not extsts 的子查询依然能用到表上的索引。
**所以无论哪个表大,用not exists都比not in要快。 **
【4】any/some/all
① any,in,some,all分别是子查询关键词之一
any 可以与=、>、>=、<、<=、<>结合起来使用,分别表示等于、大于、大于等于、小于、小于等于、不等于其中的任意一个数据。
all可以与=、>、>=、<、<=、<>结合是来使用,分别表示等于、大于、大于等于、小于、小于等于、不等于其中的其中的所有数据。
它们进行子查询的语法如下:
operand comparison_operator any (subquery); operand in (subquery); operand coparison_operator some (subquery); operand comparison_operator all (subquery);
any,all关键字必须与一个比较操作符一起使用。
② any关键词可以理解为“对于子查询返回的列中的任一数值,如果比较结果为true,则返回true”。
例如:
select age from t_user where age > any (select age from t_user_copy);
假设表t_user 中有一行包含(10),t_user_copy包含(21,14,6),则表达式为true;如果t_user_copy包含(20,10),或者表t_user_copy为空表,则表达式为false。如果表t_user_copy包含(null,null,null),则表达式为unkonwn。
all的意思是“对于子查询返回的列中的所有值,如果比较结果为true,则返回true”
例如:
select age from t_user where age > all (select age from t_user_copy);
假设表t_user 中有一行包含(10)。如果表t_user_copy包含(-5,0,+5),则表达式为true,因为10比t_user_copy中的查出的所有三个值大。如果表t_user_copy包含(12,6,null,-100),则表达式为false,因为t_user_copy中有一个值12大于10。如果表t_user_copy包含(0,null,1),则表达式为unknown。如果t_user_copy为空表,则结果为true。
③ not in /in
not in 是 “<>all”的别名,用法相同。
语句in 与“=any”是相同的。
例如:
select s1 from t1 where s1 = any (select s1 from t2); select s1 from t1 where s1 in (select s1 from t2);
语句some是any的别名,用法相同。
例如:
select s1 from t1 where s1 <> any (select s1 from t2); select s1 from t1 where s1 <> some (select s1 from t2);
在上述查询中some理解上就容易了“表t1中有部分s1与t2表中的s1不相等”,这种语句用any理解就有错了。
总结
到此这篇关于MySQL中exists、in及any基本用法的文章就介绍到这了,更多相关MySQL exists、in及any内容请搜索潘少俊衡以前的文章或继续浏览下面的相关文章希望大家以后多多支持潘少俊衡!
版权声明
本文仅代表作者观点,不代表本站立场。
本文系作者授权发表,未经许可,不得转载。
本文地址:/shujuku/MySQL/101040.html