Sql实现行列转换方便了我们存储数据和呈现数据
从MS Sql Server 2005微软就推出了pivot和unpivot实现行列转换,这极大的方便了我们存储数据和呈现数据。今天就对这两个关键字进行分析,结合实例讲解如何存储数据,如何呈现数据。
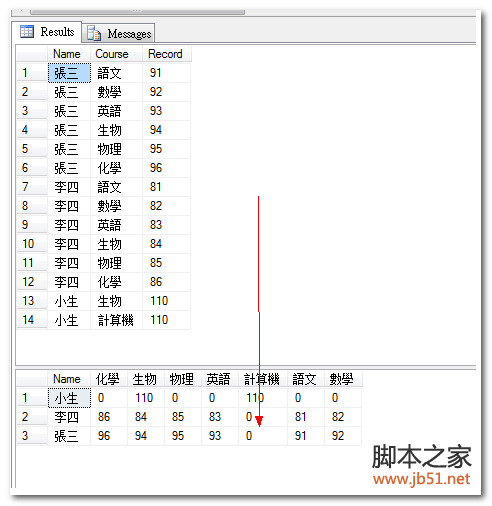
例如学生选课和成绩系统中就有一张表,该表存储了学生的课程成绩,我们无法去预料课程的多少,因此一般表会设计为下面这样:
图1

最后一列是课程编号,这样无论开学之后还会不会增加课程供学生选择,都没有关系。那么我们要呈现给用户看的报表一般是这样的:
图2

可以看到存储数据的时候采用的是列式存储,最终呈现的数据是行式显示,如何实现?下面详细分析讲解:
创建表语句
复制代码 代码如下:
USE [master]
GO
/****** Object: Table [dbo].[Table_1] Script Date: 08/06/2013 13:55:39 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
SET ANSI_PADDING ON
GO
CREATE TABLE [dbo].[Table_1](
[name] [varchar](50) NOT NULL,
[score] [real] NOT NULL,
[subject_id] [int] NOT NULL
) ON [PRIMARY]
GO
SET ANSI_PADDING OFF
GO
插入测试数据
复制代码 代码如下:
insert into [master].[dbo].[Table_1] ([name],[score],[subject_id]) values( '张三' , 90 , 1 );
insert into [master].[dbo].[Table_1] ([name],[score],[subject_id]) values( '张三' , 80 , 2 );
insert into [master].[dbo].[Table_1] ([name],[score],[subject_id]) values( '张三' , 70 , 3 );
insert into [master].[dbo].[Table_1] ([name],[score],[subject_id]) values( '王五' , 50 , 1 );
insert into [master].[dbo].[Table_1] ([name],[score],[subject_id]) values( '王五' , 40 , 2 );
insert into [master].[dbo].[Table_1] ([name],[score],[subject_id]) values( '李四' , 60 , 1 );
现在查询下Table_1中的数据即为图1中的结果,现在我们要得到图2的结果,那么使用下面的语句:
复制代码 代码如下:
SELECT [name],[1],[2],[3]
FROM [master].[dbo].[Table_1]
pivot
(
sum(score) for subject_id in ([1],[2],[3])
) as pvt
GO
如果本身数据库表存储的就是图2那样,要变成图1的方式呈现,那就需要用unpivot,可以这样做:
复制代码 代码如下:
SELECT [name],[subject_id],[score]
FROM
(
SELECT [name],[1],[2],[3]
FROM [master].[dbo].[Table_1]
pivot
(
sum(score) for subject_id in ([1],[2],[3])
) as pvt
) p
unpivot
(
score for subject_id in([1],[2],[3])
) as unpvt
当然我还是在Table_1的基础上先用pvt转为为行式存储的方式,再用unpivot进行列式呈现。
例如学生选课和成绩系统中就有一张表,该表存储了学生的课程成绩,我们无法去预料课程的多少,因此一般表会设计为下面这样:
图1
最后一列是课程编号,这样无论开学之后还会不会增加课程供学生选择,都没有关系。那么我们要呈现给用户看的报表一般是这样的:
图2
可以看到存储数据的时候采用的是列式存储,最终呈现的数据是行式显示,如何实现?下面详细分析讲解:
创建表语句
复制代码 代码如下:
USE [master]
GO
/****** Object: Table [dbo].[Table_1] Script Date: 08/06/2013 13:55:39 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
SET ANSI_PADDING ON
GO
CREATE TABLE [dbo].[Table_1](
[name] [varchar](50) NOT NULL,
[score] [real] NOT NULL,
[subject_id] [int] NOT NULL
) ON [PRIMARY]
GO
SET ANSI_PADDING OFF
GO
插入测试数据
复制代码 代码如下:
insert into [master].[dbo].[Table_1] ([name],[score],[subject_id]) values( '张三' , 90 , 1 );
insert into [master].[dbo].[Table_1] ([name],[score],[subject_id]) values( '张三' , 80 , 2 );
insert into [master].[dbo].[Table_1] ([name],[score],[subject_id]) values( '张三' , 70 , 3 );
insert into [master].[dbo].[Table_1] ([name],[score],[subject_id]) values( '王五' , 50 , 1 );
insert into [master].[dbo].[Table_1] ([name],[score],[subject_id]) values( '王五' , 40 , 2 );
insert into [master].[dbo].[Table_1] ([name],[score],[subject_id]) values( '李四' , 60 , 1 );
现在查询下Table_1中的数据即为图1中的结果,现在我们要得到图2的结果,那么使用下面的语句:
复制代码 代码如下:
SELECT [name],[1],[2],[3]
FROM [master].[dbo].[Table_1]
pivot
(
sum(score) for subject_id in ([1],[2],[3])
) as pvt
GO
如果本身数据库表存储的就是图2那样,要变成图1的方式呈现,那就需要用unpivot,可以这样做:
复制代码 代码如下:
SELECT [name],[subject_id],[score]
FROM
(
SELECT [name],[1],[2],[3]
FROM [master].[dbo].[Table_1]
pivot
(
sum(score) for subject_id in ([1],[2],[3])
) as pvt
) p
unpivot
(
score for subject_id in([1],[2],[3])
) as unpvt
当然我还是在Table_1的基础上先用pvt转为为行式存储的方式,再用unpivot进行列式呈现。
版权声明
本文仅代表作者观点,不代表本站立场。
本文系作者授权发表,未经许可,不得转载。
本文地址:/shujuku/MsSQL/107845.html