MongoDB入门教程(包含安装、常用命令、相关概念、使用技巧、常见操作等)
一、安装和配置
MongoDB 的官方下载站是 http://www.mongodb.org/downloads,可以去上面下载最新的安装程序
Windows 平台的安装
● 步骤一: 下载 MongoDB
点击上方官方下载地址, 并下载 Windows 版本
● 步骤二: 设置 MongoDB 程序存放目录
下载完成后, 解压到自定义文件夹,例: D:\mongodb\
● 步骤三: 设置数据文件存放目录
在 D:\mongodb\ 目录下创建 db 和 logs 文件夹 (和 bin 目录同级),
随后在 logs 文件夹内创建 mongodb.log 日志文件
● 步骤四: 启动 MongoDB 服务, 作为 Windows 服务
复制代码 代码如下:
//进入 cmd 控制台
D:/mongodb/bin>mongod.exe --logpath D:/mongodb/logs/mongodb.log --logappend
--dbpath D:/mongodb/db
--directoryperdb
--serviceName MongoDB
--install
--directoryperdb 指定每个DB都会新建一个目录
安装完成后,就可以在 cmd 下用命令 net start MongoDB 和 net stop MongoDB 来启动和停止 MongoDB 了
● 步骤五: 客户端连接验证
打开 cmd 输入: D:/mongodb/bin>mongo.exe
复制代码 代码如下:
D:/mongodb/bin>mongo.exe
MongoDB shell version: 2.4.8
connecting to: test
>
Linux 平台的安装
● 步骤一: 下载 MongoDB
点击上方官方下载地址, 并下载 Linux 版本
● 步骤二: 设置 MongoDB 程序存放目录
下载完成后, 解压到自定义文件夹,例: /usr/local/mongo
● 步骤三: 设置数据文件存放目录
创建 /data/db 和 /data/logs 文件夹, 随后在 logs 文件夹内创建 mongodb.log 日志文件
● 步骤四: 启动 MongoDB 服务, 作为 Linux 服务随机启动
复制代码 代码如下:
vi /etc/rc.local //使用vi 编辑器打开配置文件,并在其中加入下面一行代码
/usr/local/mongo/bin/mongod --dbpath=/data/db/ --logpath=/data/logs/mongodb.log --logappend&
安装完成后, 可以使用 pkill mongod 来结束
二、数据逻辑结构
● MongoDB 的文档(document),相当于关系数据库中的一行记录。
● 多个文档组成一个集合(collection),相当于关系数据库的表。
● 多个集合(collection),逻辑上组织在一起,就是数据库(database)。
● 一个 MongoDB 实例支持多个数据库(database)。
● 默认端口: 27017
三、常用命令
选择数据库
复制代码 代码如下:use persons
显示当前数据库
复制代码 代码如下:db || db.getName()
删除当前数据库
复制代码 代码如下:db.dropDatabase()
显示当前数据库下的集合 Collections
复制代码 代码如下:
show tables || show collections
显示当前 system.profile
复制代码 代码如下:
show profile
显示当前数据库下的用户 Users
复制代码 代码如下:
show users
添加用户
复制代码 代码如下:
db.addUser(username, password)
删除用户
复制代码 代码如下:
db.removeUser(username)
四、索引 ensureIndex()
复制代码 代码如下:
//普通索引
db.persons.ensureIndex({name:1});
db.factories.insert({name: "xyz", metro: {city: "New York", state: "NY"}});
//文档式索引
db.factories.ensureIndex({metro : 1});
//嵌入式索引
db.factories.ensureIndex({"metro.city": 1});
//组合索引
db.things.ensureIndex({name: -1, qty: 1});
//唯一索引
db.user.ensureIndex({firstname: 1, lastname: 1}, {unique: true});
/* 当一个记录被插入到唯一性索引文档时,缺失的字段会以null为默认值被插入文档 */
db.things.save({lastname: "Smith"});
//下面这个操作将会失败,因为 firstname 上有唯一性索引,值为 null
db.things.save({lastname: "Jones"});
//查看索引
db.persons.getIndexes();
//删除所有索引
db.collection.dropIndexes();
//删除单个索引
db.collection.dropIndex({x: 1, y: -1});
五、增删改查等
复制代码 代码如下:
//定义文档
>doc = {
"_id" : 1,
"author" : "sam",
"title" : "i love you",
"text" : "this is a test",
"tags" : [ "love", "test" ],
"comments" : [
{ "author" : "jim", "comment" : "yes" },
{ "author" : "tom", "comment" : "no" }
]
}
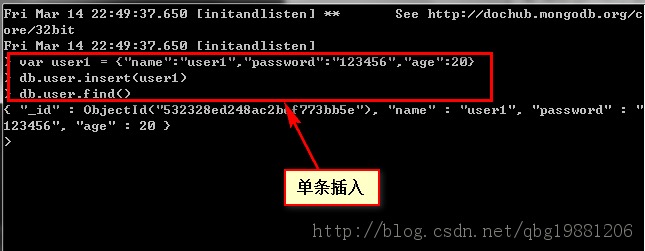
//插入文档
> db.posts.insert(doc);
//查找文档
> db.posts.find({'comments.author':'jim'});
查询 Query
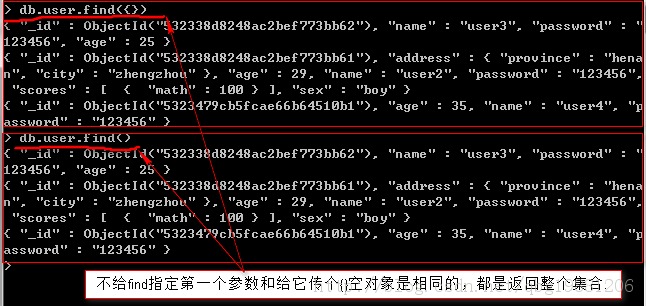
复制代码 代码如下://查询集合中的所有记录:
db.users.find({})
//查询出所有 “last_name” 属性值为 “Smith” 的文档记录
db.users.find({'last_name': 'Smith'})
查询选项
复制代码 代码如下://返回除了 age 字段外的所有字段
> db.user.find( {},{ age : 0 } );
//返回 tags=tennis 除了 comments 的所有列
> db.posts.find( { tags : 'tennis' }, { comments : 0 } );
//返回 userid=16 的 name 字段
> db.user.find( { userid : 16 },{ name : 1 } );
//返回结果:
{ "_id" : 16, "name" : "user16" }
//返回 x=john 的所有 z 字段
> db.things.find( { x : "john" }, { z : 1 } );
//注: _id字段始终都会被返回,哪怕没有明确指定
条件表达式
1) <, <=, >, >=
复制代码 代码如下:
// 大于: field > value
> db.collection.find( { "field" : { $gt : value } } );
//小于:field < value
> db.collection.find( { "field" : { $lt : value } } );
//大于等于: field >= value
> db.collection.find( { "field" : { $gte : value } } );
//小于等于:field <= value
> db.collection.find( { "field" : { $lte : value } } );
//区间查询 5 < field <= 10
> db.collection.find( { "field" : { $gt : 5, $lte : 10 } } );
$all 操作类似 $in 操作,但是不同的是,$all操作要求数组里面的值全部被包含在返回的记录里面
复制代码 代码如下:> use test;
switched to db test
> db.things.insert( { a : [ 1, 2, 3 ] } );
> db.things.find();
{ "_id" : ObjectId("4de73360059e7f4bdf907cfe"), "a" : [ 1, 2, 3 ] }
> db.things.find( { a : { $all : [ 2, 3 ] } } );
{ "_id" : ObjectId("4de73360059e7f4bdf907cfe"), "a" : [ 1, 2, 3 ] }
> db.things.find( { a : { $all : [ 1, 2, 3 ] } } );
{ "_id" : ObjectId("4de73360059e7f4bdf907cfe"), "a" : [ 1, 2, 3 ] }
> db.things.find( { a : { $all : [ 1 ] } } );
{ "_id" : ObjectId("4de73360059e7f4bdf907cfe"), "a" : [ 1, 2, 3 ] }
> db.things.find( { a : { $all : [ 1, 2, 3, 4 ] } } );
>
>
$exists 操作检查一个字段是否存在
复制代码 代码如下:
//userid 字段存在
> db.user.find( { userid : { $exists : true } } ).limit(1);
{ "_id" : 1, "name" : "user1", "userid" : 1, "age" : 20 }
//sex 字段不存在
> db.user.find( { sex : { $exists : true } } ).limit(1);
>
>
$mod 操作可以让我们简单的进行取模操作
复制代码 代码如下://where子句
> db.user.find( "this._id%10==1" ).limit(5);
//$mod操作
> db.user.find( { _id : { $mod : [ 10, 1 ] } } ).limit(5);
$ne 意思是 不等于 (not equal)
复制代码 代码如下:> db.user.find().limit(2);
{ "_id" : 0, "name" : "user0", "userid" : 0, "age" : 20 }
{ "_id" : 1, "name" : "user1", "userid" : 1, "age" : 20 }
> db.user.find( { _id : { $ne : 0 } } ).limit(2);
{ "_id" : 1, "name" : "user1", "userid" : 1, "age" : 20 }
$in 操作类似于传统关系数据库中的IN
复制代码 代码如下://数据库中有所有数组对应的记录
> db.user.find( { _id : { $in : [ 2, 3 ] } } ).limit(5);
{ "_id" : 2, "name" : "user2", "userid" : 2, "age" : 20 }
{ "_id" : 3, "name" : "user3", "userid" : 3, "age" : 20 }
$nin 跟 $in 操作相反
复制代码 代码如下:
//扣掉 _id = 1/2/3/4 的记录
> db.user.find( { _id : { $nin : [ 1, 2, 3, 4 ] } } ).limit(5);
{ "_id" : 0, "name" : "user0", "userid" : 0, "age" : 20 }
{ "_id" : 5, "name" : "user5", "userid" : 5, "age" : 20 }
{ "_id" : 6, "name" : "user6", "userid" : 6, "age" : 20 }
$or
复制代码 代码如下:> db.user.find( { $or : [ { _id : 2 }, { name : 'user3' }, { userid : 4 } ] } ).limit(5);
{ "_id" : 2, "name" : "user2", "userid" : 2, "age" : 20 }
{ "_id" : 3, "name" : "user3", "userid" : 3, "age" : 20 }
{ "_id" : 4, "name" : "user4", "userid" : 4, "age" : 20 }
>
$nor 跟 $or 相反
复制代码 代码如下:> db.user.find( { $nor : [ { _id : 2 }, { name : 'user3' }, { userid : 4 } ] } ).limit(4);
{ "_id" : 0, "name" : "user0", "userid" : 0, "age" : 20 }
{ "_id" : 1, "name" : "user1", "userid" : 1, "age" : 20 }
{ "_id" : 5, "name" : "user5", "userid" : 5, "age" : 20 }
{ "_id" : 6, "name" : "user6", "userid" : 6, "age" : 20 }
>
$size 操作将会查询数组长度等于输入参数的数组
复制代码 代码如下:> db.things.find();
{ "_id" : ObjectId("4de73360059e7f4bdf907cfe"), "a" : [ 1, 2, 3 ] }
> db.things.find( { a : { $size : 3 } } );
{ "_id" : ObjectId("4de73360059e7f4bdf907cfe"), "a" : [ 1, 2, 3 ] }
> db.things.find( { a : { $size : 2 } } );
>
> db.things.find( { a : { $size : 1 } } );
>
$where
复制代码 代码如下:> db.mycollection.find( { $where : function() { return this.a == 3 || this.b == 4; } } );
//同上效果
> db.mycollection.find( function() { return this.a == 3 || this.b == 4; } );
$type 将会根据字段的 BSON 类型来检索数据
复制代码 代码如下:
//返回 a 是字符串的记录
> db.things.find( { a : { $type : 2 } } );
//返回 a 是 int 类型的记录
> db.things.find( { a : { $type : 16 } } );
类型名称映射
● Double : 1
● String : 2
● Object : 3
● Array : 4
● Binary data : 5
● Object id :7
● Boolean :8
● Date :9
● Null : 10
● Regular expression : 11
● JavaScript code : 13
● Symbol : 14
● JavaScript code with scope : 15
● 32-bit integer : 16
● Timestamp : 17
● 64-bit integer : 18
● Min key : 255
● Max key : 127
Mongodb同样支持正则表达式进行检索
复制代码 代码如下:
//检索name属性是以 u 开头,4 结尾的所有用户
> db.user.find( { name : /u.*4$/i } ).limit(2);
{ "_id" : 4, "name" : "user4", "userid" : 4, "age" : 20 }
{ "_id" : 14, "name" : "user14", "userid" : 14, "age" : 20 }
//同样效果的查询语句
> db.user.find( { name : { $regex : 'u.*4$', $options : 'i' } } ).limit(2);
{ "_id" : 4, "name" : "user4", "userid" : 4, "age" : 20 }
{ "_id" : 14, "name" : "user14", "userid" : 14, "age" : 20 }
//配合其他操作一起使用
> db.user.find( { name : { $regex : 'u.*4$', $options : 'i', $nin : [ 'user4' ] } } ).limit(2);
{ "_id" : 14, "name" : "user14", "userid" : 14, "age" : 20 }
排序
按照 last_name 属性进行升序排序返回所有文档
复制代码 代码如下:
//1表示升序,-1表示降序
db.users.find( {} ).sort( { last_name : 1 } );
Group
复制代码 代码如下://语法:
db.coll.group( {
cond : {filed:conditions},
key : {filed: true},
initial : {count: 0, total_time:0},
reduce : function(doc, out){ },
finalize : function(out){}
} );
参数说明:
Key :对那个字段进行
Group Cond :查询条件
Initial :初始化group计数器
Reduce :通常做统计操作
Finalize :通常都统计结果进行进一步操作,例如求平均值 Keyf:用一个函数来返回一个替代 KEY 的值
//例子
> db.test.group( {
cond : { "invoked_at.d" : { $gte : "2009-11", $lt : "2009-12" } },
key : {http_action: true},
initial : {count: 0, total_time:0},
reduce : function( doc, out ){ out.count++; out.total_time += doc.response_time },
finalize : function(out){ out.avg_time = out.total_time / out.count } } );
[
{
"http_action" : "GET /display/DOCS/Aggregation",
"count" : 1,
"total_time" : 0.05,
"avg_time" : 0.05
}
]
去重 类似于关系数据库中的 Distinct
复制代码 代码如下:> db.addresses.insert( { "zip-code" : 10010 } )
> db.addresses.insert( { "zip-code" : 10010 } )
> db.addresses.insert( { "zip-code" : 99701 } )
>
> db.addresses.distinct("zip-code");
[ 10010, 99701 ]
>
> //command 模式:
> db.runCommand( { distinct: 'addresses', key: 'zip-code' } )
{ "values" : [ 10010, 99701 ] }
>
> db.comments.save( { "user" : { "points" : 25 } } )
> db.comments.save( { "user" : { "points" : 31 } } )
> db.comments.save( { "user" : { "points" : 25 } } )
> db.comments.distinct("user.points");
[ 25, 31 ]
Mongodb 支持 skip 和 limit 命令来进行分页查询
复制代码 代码如下://跳过前10条记录
> db.user.find().skip(10);
//每页返回8条记录
> db.user.find().limit(8);
//跳过前20条记录,并且每页返回10条记录
> db.user.find().skip(20).limit(8);
//下面这个语句跟上一条一样,只是表达不够清晰
> db.user.find({}, {}, 8, 20);
$elemMatch
复制代码 代码如下:> t.find( { x : { $elemMatch : { a : 1, b : { $gt : 1 } } } } )
{ "_id" : ObjectId("4b5783300334000000000aa9"), "x" : [ { "a" : 1, "b" : 3 }, 7, { "b" : 99 }, { "a" : 11 } ] }
//同样效果
> t.find( { "x.a" : 1, "x.b" : { $gt : 1 } } )
count()方法返回查询记录的总数
复制代码 代码如下:
db.orders.count( { ord_dt : { $gt : new Date('01/01/2012') } } )
//同样效果
db.orders.find( { ord_dt : { $gt : new Date('01/01/2012') } } ).count()
//当查询语句用到了 skip() 和 limit() 方法的时候,
//默认情况下 count() 会忽略这些方法,如果想要计算这些方法,
//需要给 count() 方法传一个 true 作为参数
> db.user.find( { _id : { $lt : 20 } } ).skip(3).limit(9).count();
20
> db.user.find( { _id : { $lt : 20 } } ).skip(3).limit(9).count(true);
9
>
$slice
复制代码 代码如下:
db.posts.find({}, {comments:{$slice: 5}}) // 前5条评论
db.posts.find({}, {comments:{$slice: -5}}) //后5条评论
db.posts.find({}, {comments:{$slice: [20, 10]}}) // 跳过20条, limit 10
db.posts.find({}, {comments:{$slice: [-20, 10]}}) // 后20条, limit 10
删除 Delete
Remove 操作用于从集合中删除记录
复制代码 代码如下:
//删除一条记录
> db.stu.remove( { _id : 17 } );
//删除所有记录
> db.stu.remove( {} );
//某些情况下,当你在对一个记录执行 remove 操作的时候,
//可能会有 update 操作在这个记录上,这样就可能删除不掉这个记录,
//如果你觉得这不尽人意,那么你可以在 remove 操作的时候加上 $atomic:
db.stu.remove( { rating : { $lt : 3.0 }, $atomic : true } );
更新 Update
复制代码 代码如下:
db.collection.update( criteria, objNew, upsert, multi )
参数说明:
Criteria :用于设置查询条件的对象
Objnew :用于设置更新内容的对象
Upsert :如果记录已经存在,更新它,否则新增一个记录
Multi :如果有多个符合条件的记录,全部更新 注意:默认情况下,只会更新第一个符合条件的记录
save()
复制代码 代码如下:
//如果存在更新它,如果不存在,新增记录
db.mycollection.save( { name : 'shawn' } );
$inc
复制代码 代码如下:
{ $inc : { field : value } } //把field的值加一个value
> db.user.findOne( { _id : 0 } );
{ "_id" : 0, "name" : "user0", "userid" : 0, "age" : 22 }
> db.user.update( { _id : 0 }, { $inc : { age : 1 } } );
{ "_id" : 0, "name" : "user0", "userid" : 0, "age" : 23 }
$set
复制代码 代码如下:
{ $set : { field : value } }
// 把field的值设置成value,当field不存在时,增加一个字段,
// 类似SQL的set操作,value支持所有类型
// 把上面的 age 改回到 20
> db.user.update( { _id : 0 }, { $set : { age : 20 } } );
{ "_id" : 0, "name" : "user0", "userid" : 0, "age" : 20 }
// 当 field 不存在时,增加一个字段
> db.user.update( { _id : 0 }, { $set : { sex : 'boy' } } );
{ "_id" : 0, "sex" : "boy", "name" : "user0", "userid" : 0, "age" : 20 }
$unset
复制代码 代码如下:
{ $unset : { field : 1} } // 删除给定的字段field
//删除上一步增加的sex字段
> db.user.update( { _id : 0 }, { $unset : { sex : 1 } } );
{ "_id" : 0, "name" : "user0", "userid" : 0, "age" : 20 }
$push
复制代码 代码如下:
{ $push : { field : value } }
// 如果 filed 是一个已经存在的数组,那么把 value 追加给 field
// 如果 field 原来不存在,那么新增 field 字段,把value的值赋给field
// 如果 field 存在,但是不是一个数组,将会出错
> db.sport.update( { _id : 0 }, { $push : { aihao : 'football' } } );
$pushAll
复制代码 代码如下:
{ $pushAll : { field : value_array } }
// 功能同$push,只是这里的 value 是数组,相当于对数组里的每一个值进行 $push 操作
$addToSet
复制代码 代码如下:
{ $addToSet : { field : value } }
// 如果 filed 是一个已经存在的数组,并且 value 不在其中,那么把 value 加入到数组
// 如果 filed 不存在,那么把 value 当成一个数组形式赋给 field
// 如果 field 是一个已经存在的非数组类型,那么将会报错
$pop
复制代码 代码如下:
{ $pop : { field : 1 } } //删除数组中最后一个元素
{ $pop : { field : -1 } } //删除数组中第一个元素
$pull
复制代码 代码如下:
{ $pull : { field : _value } }
// 如果 field 是一个数组,那么删除符合 _value 检索条件的记录
// 如果 field 是一个已经存在的非数组,那么会报错
$pullAll
复制代码 代码如下:
{ $pullAll : { field : value_array } } //同$push类似,只是value的数据类型是一个数组
$rename
复制代码 代码如下:
{ $rename : { old_field_name : new_field_name }
// 重命名指定的字段名称,从1.7.2版本后开始支持
> db.user.update( { _id : 0 } , { $rename : { 'quantity' : 'qty'}});
特殊操作符:$
$ 操作符代表查询记录中第一个匹配条件的记录项
复制代码 代码如下:
//例1
> db.t.find()
{
"_id" : ObjectId("4b97e62bf1d8c7152c9ccb74"),
"title" : "ABC",
"comments" : [
{ "by" : "joe", "votes" : 3 },
{ "by" : "jane", "votes" : 7 }
]
}
> db.t.update( { 'comments.by' : 'joe' }, { $inc : { 'comments.$.votes' : 1 } }, false, true )
> db.t.find()
{
"_id" : ObjectId("4b97e62bf1d8c7152c9ccb74"),
"title" : "ABC",
"comments" : [
{ "by" : "joe", "votes" : 4 },
{ "by" : "jane", "votes" : 7 }
]
}
//例2
> db.t.find();
{
"_id" : ObjectId("4b9e4a1fc583fa1c76198319"),
"x" : [ 1, 2, 3, 2 ]
}
> db.t.update( { x : 2 }, { $inc : { "x.$": 1 } }, false, true);
> db.t.find();
{
"_id" : ObjectId("4b9e4a1fc583fa1c76198319"),
"x" : [ 1, 3, 3, 2 ]
}
//在数组中用 $ 配合 $unset操作 符的时候,效果不是删除匹配的元素,而是把匹配的元素变成了null,如:
> db.t.insert( { x: [ 1, 2, 3, 4, 3, 2, 3, 4 ] } )
> db.t.find()
{
"_id" : ObjectId("4bde2ad3755d00000000710e"),
"x" : [ 1, 2, 3, 4, 3, 2, 3, 4 ]
}
> db.t.update( { x : 3 }, { $unset : { "x.$" : 1 } } )
> t.find()
{
"_id" : ObjectId("4bde2ad3755d00000000710e"),
"x" : [ 1, 2, null, 4, 3, 2, 3, 4 ]
}
图形化管理工具
MongoDB有几款图形化的管理工具,参考:
http://docs.mongodb.org/ecosystem/tools/administration-interfaces/
版权声明
本文仅代表作者观点,不代表本站立场。
本文系作者授权发表,未经许可,不得转载。
本文地址:/shujuku/MongoDB/105513.html