mongodb 常见问题处理方法收集
1 非正常关闭服务或关机后 mongod服务无法正常启动
在使用中发现mongodb 的服务很容易因为非正常关闭而启动不了,不过解决也很容易
删除data目录下的 *.lock文件,再运行下 /mongodb_binpath/mongod -repair -f config文件路径 再启动即可
也可以在/etc/init.d/mongod 服务启动的文件中加入 启动前删除该文件 如下:
start() {
rm -f /usr/mongodb/data/master/mongod.lock
/usr/mongodb/bin/mongod --config /usr/mongodb/config/master.conf
}
2、server-side JavaScript execution is disabled
完整信息:JavaScript execution failed: group command failed: { "ok" : 0, "errmsg" : "server-side JavaScript execution is disabled" }
解决方法:mongod.conf 这个配置文件里 noscripting:false 如果true 就是禁止
3、 Decimal转换成BsonValue值异常
BsonValue 暂不支持 Decimal类型,转换前强制转换类型,
if (type==typeof(Decimal))
{
return Convert.ToDouble(value);
}
如果用MongoDB,最好不要用decimal类型,否则在序列化的时候也有问题,可用double
4、MONGO Replica 频繁插入大数据的问题
MONGO Replica 频繁插入大数据的问题,当在复制集中频繁插入大数据时有可能出现 “error RS102 too stale to catch up"出现这个错误的原因是SECONDARY即副节点的复制速度跟不上了,当需要批量频繁向副本集中写入数据时最好先移除副本节点,待插入完后重新同步。
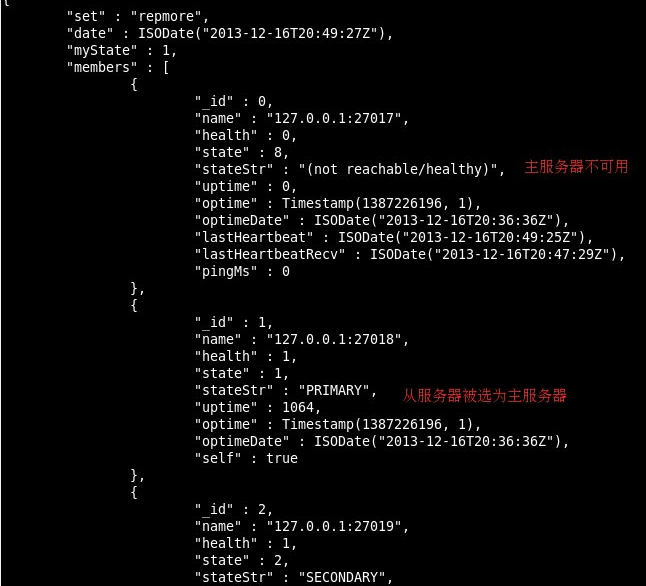
5 Mongo集群没有primary但有secondary时连接不上且不能读数据
#mongodb默认是从主节点读写数据的,副本节点上不允许读,需要设置副本节点可以读。
shell
1 repset:SECONDARY> db.getMongo().setSlaveOk(); #要在primary上执行
2 rs.slaveOk()
其他客户端
从secondary 读数据
如果应用程序没有设置相应的ReadReference也可能不能进行读取操作
MongoClientSettings set = new MongoClientSettings();
List
servers.Add(new MongoServerAddress("192.168.129.129", 37017));
servers.Add(new MongoServerAddress("192.168.129.129", 37018));
servers.Add(new MongoServerAddress("192.168.129.129", 37019));
set.Servers = servers;
//设置副本集名称
set.ReplicaSetName = "rs0";
//设置超时时间为3秒
set.ConnectTimeout = new TimeSpan(0, 0, 0, 3, 0);
MongoClient client = new MongoClient(set);
MongoServer server = client.GetServer();
MongoDatabase db = server.GetDatabase("test");
MongoCollection coll = db.GetCollection("test");
注:设置驱动的ReadReference也可以通过MongoDB连接字符串配置:mongodb://example1.com,example2.com,example3.com/?readPreference=secondary。通过连接字符串指定的read preference是针对整个连接。
set.ReadPreference = new ReadPreference(ReadPreferenceMode.PrimaryPreferred);
将ReadPreferenceMode设置成Secondary或SecondaryPreferred
下面是其他网友的补充:
一、
1. addshard 遇到的错误 db.runCommand({addshard:”172.16.5.104:20000″}) { “ok” : 0, “errmsg” : “can't use localhost as a shard since all shards need to communicate. either use all shards and configdbs in localhost or all in actual IPs host: 172.16.5.104:20000 isLocalHost:0″ } 遇到这样的错误是由于某些服务启动在 localhost 地址。 经过检查发现 route 启动时,读取 config 服务是读取的 localhost 地址: ./mongos –port 40000 –configdb localhost:30000 –fork [...]
1. addshard 遇到的错误
db.runCommand({addshard:”172.16.5.104:20000″})
{
“ok” : 0,
“errmsg” : “can't use localhost as a shard since all shards need to communicate. either use all shards and configdbs in localhost or all in actual IPs host: 172.16.5.104:20000 isLocalHost:0″
}
遇到这样的错误是由于某些服务启动在 localhost 地址。
经过检查发现 route 启动时,读取 config 服务是读取的 localhost 地址:
./mongos –port 40000 –configdb localhost:30000 –fork –logpath /data/route/log/route.log –chunkSize 1
将 localhost 修改为 IP 地址,问题解决。
2. 为什么要同时有 config 和 route
一开始看到 config 和 route 的逻辑结构有一点疑惑。既然一个数据库查询的过程是:
客户端
|
route
|
config
|
Database
而 config 的作用就是告诉 route 应该去哪一个 Database 取数据。那么为什么不能直接由客户端向 config 发起请求呢?这时 route 的存在岂不是多余?
简单的思考之后,得出了以下结论:
在有多个 route 和多个 config 的情况下,route 与 route 之间是平行的存在,也就是说,一个 route 并不知道另外一个 route 的存在。但是一个 route 知道所有 config 的存在。
那么当要写入数据时,只要你是通过了 route,route 就会通知到所有的 config,那么每一个 config 便会知道数据是如何分片的。
如果将 route 这层去掉,那么 config 与 config 之间并不知道彼此的存在。客户端的请求很可能会只发向其中的一个 config,那么也只有这一个 config 知道最新的分片状态。
这个答案其实经不起太多的推敲,比如:
config 是可以从客户端那里拿到所有 config 的列表的,一旦有了列表之后,config 就可以彼此相互通信了。可以解决数据同步的问题。
我还要看多一些文档。
3. Replica Set 启动顺序
在启动两个 rs 机器时,我先启动了 second,后启动了 Primary。这是一台机器上显示自己为 second,另外一台为 unreachable。而另外一台机器显示两台机器均在 second。
这个现象需要验证,是否 Replica Set 是有启动顺序限制。
二、
昨天到今天一直在尝试在同一台机器上用多个IP地址来创建 Replica Set + Shard。 由于 MongoDB 官方用户验证方面的文档说的也不太细。所以走了一些回头路。 下面整理一些常见的错误,以及他们可能表达的意思。描述的顺序是按照排错的逻辑: 1. route 启动的时候,连接 config 不可以以 localhost 为地址链接。不然会遇到以下错误: “errmsg” : “can't use localhost as a shard since all shards need to communicate. either use all shards and configdbs in localhost or all in actual IPs host: 172.16.5.104:20000 isLocalHost:0″ 2. 如果不以 localhost 为地址链接,那么 config 启动的时候不能加 –auth 选项,不然会在log文件中遇到以下错误: ERROR: [...]
昨天到今天一直在尝试在同一台机器上用多个IP地址来创建 Replica Set + Shard。
由于 MongoDB 官方用户验证方面的文档说的也不太细。所以走了一些回头路。
下面整理一些常见的错误,以及他们可能表达的意思。描述的顺序是按照排错的逻辑:
1. route 启动的时候,连接 config 不可以以 localhost 为地址链接。不然会遇到以下错误:
“errmsg” : “can't use localhost as a shard since all shards need to communicate. either use all shards and configdbs in localhost or all in actual IPs host: 172.16.5.104:20000 isLocalHost:0″
2. 如果不以 localhost 为地址链接,那么 config 启动的时候不能加 –auth 选项,不然会在log文件中遇到以下错误:
ERROR: config servers not in sync! not authorized, did you start with –keyFile?
此时进程无法启动
3.在 route 和 config 准备完毕后,通过 route 以远程 IP 为地址添加shard,则报错:(有 –auth 参数)
db.runCommand({addshard:'a1:28010′})
{
“ok” : 0,
“errmsg” : “failed listing a1:28010′s databases:{ errmsg: \”need to login\”, ok: 0.0 }”
}
4. 去掉 –auth 参数,添加 shard,成功!
5. 依旧保留 –auth 参数,添加用户后,再添加shard。报错:
“errmsg” : “couldn't connect to new shard DBClientBase::findN: transport error: a1:28010 query: { getlasterror: 1 }”
总结:MongoDB 2.0 的认证方式
1.Replica Set 之间通过 key 来相互认证。
2.Route 与 Config 之间不存在认证关系,Route 连接 Config 时不能以 localhost 连接。
3.单个Mongod进程启动后,如果无 –auth 选项且无用户,则必须通过 localhost 连接才能添加用户和做其他操作。如果通过远程(非127.0.0.1的IP地址)连接,则必须要输入用户名、密码。此时如果还无用户存在,则无法连接。
4.添加 Shard 时,mongod 不可以带 –auth 参数,不然会添加失败。
三、
续上篇 笔记2 ,还是说一下关于 MongoDB 认证的问题。 在 王文龙 所写的 《MongoDB 实战》 中,写到: 创建主从 key 文件,用于标识集群的私钥的完整路径,如果各个实例的 key file 内容不一 致,程序将不能正常用。 我误以为 –keyFile 是各个节点之间的认证方式。其实不是的。各个节点之间的确认关系参数是 –replSet。只要此参数后面的内容一致。Replica Set 就可以创建成功。 在官方文档中提到: You do not need to use the –auth option, too (although there's no harm in doing so), –keyFile implies –auth. –auth does not imply –keyFile. 也就是说 keyFile 其实包含了 auth 的作用。 [...]
续上篇 笔记2 ,还是说一下关于 MongoDB 认证的问题。
在 王文龙 所写的 《MongoDB 实战》 中,写到:
创建主从 key 文件,用于标识集群的私钥的完整路径,如果各个实例的 key file 内容不一 致,程序将不能正常用。
我误以为 –keyFile 是各个节点之间的认证方式。其实不是的。各个节点之间的确认关系参数是 –replSet。只要此参数后面的内容一致。Replica Set 就可以创建成功。
在官方文档中提到:
You do not need to use the –auth option, too (although there's no harm in doing so), –keyFile implies –auth. –auth does not imply –keyFile.
也就是说 keyFile 其实包含了 auth 的作用。
而当你加了 –keyFile 参数后,如果你要添加 Shard,则会收到报错:
need to login
这和加了 auth 的报错一致。
以前没接触过 MongoDB,直接从 2.0 使用,所以里面的有些细节可能还不理解。看到有人说 auth 是 2.0 的新功能。而之前只能用 keyFile 验证。还不太清楚 keyFile 下用户登陆的一些细节。
MongoDB 常见问题处理
说明: 这里的问题是我在看MongoDB官网文章时,从里面总结出来的。
mongod process "disappeared":
这个说的是mongodb进行消失,可以理解为死掉等。可以从下面中找问题在
#grep mongod /var/log/messages
#grep score /var/log/messages
Socket errors in sharded clusters and replica sets:
echo 300 > /proc/sys/net/ipv4/tcp_keepalive_time 默认是7200
关于tomm many open files:
First:检查以下几项:
lsof | grep mongod
lsof | grep mongod | grep TCP
lsof | grep mongod | grep data | wc
可以用:ulimit解决: ulimit -n X
High TCP Connection Count:
TCP Connection过大时,可以检查是不是client apps使用连接池问题
Mongod (hard) connection limit
这个连接数限制在20000,可以手动调整大小
Data files count with very large databases
数据在T级以上时,确定是否做了限制(手动增加),再用repairdatabase时,会同时有2 copies
No space left on device
这个时候reads仍然在进行,要做的是first shutdown servers, then to delete some data and compact
Checking Siez of a collection(检查集合)
>db.(collectionname).validate();
NUMA:
Linu,
Numa and MongoDB不能很好的一起工作。如果机器在numa硬件运行的时候,需要把它关闭。一般出现大规模性能慢下来或一段时间cpu占用很高的system time 。可以从日志中抓取NUMA字。(我也翻译不出这个NUMA是什么意思)
关闭的方法:
一:在启动mongoDB的时候:
numactl --interleave=all ${MONGODB_HOME}/bin/mongod --config conf/mongodb.conf
二:在不关闭mongoDB时:
echo 0 > /proc/sys/vm/zone_reclaim_mod
案例:
https://www.jb51.net/article/109199.htm
或https://www.jb51.net/article/109198.htm
NFS:
官网不建意采用NFS系统文件运行mongoDB,因为NFS版本问题会导致性能很低或无法工作
SSD:
mongoDB在SSD(固态硬盘)运行很快,但是比RAM低。可以用mongoperf进行硬盘性能状态分析。
Virtualization:
mongoDB在虚拟化上运行的很好,如OpenVZ 兼容EC2 ,VMWare也可以但是clone的时候会出现一些问题由其在a member of a replica set(一个复制节点上),要想可用的,需要journaling处在可用状态,再进行clone。如果没有的开启journaling的时候,stop m ongod ,clone, and tehn restart
注意:在MongoDB中要用IP地址不要使用机器名或localhost,不然会出现链接不数据库的。
Journal(日志):
日志的开启:--journal ;关闭:--nojournal ,默认时间是100ms
启动时会在数据目录下创建一个journal地文件目录,在受到毁坏时,再启动mongoDB不需要再运行repair,它会自动恢复的。
可以通过运行journalLatencyTest测试写入磁盘的性能和同步性能。
>use admin
>db.runCommand("journalLatencyTest")
Backup with --journal 中journal是支持回滚恢复。
journaling的时候,stop m ongod ,clone, and tehn restart
注意:在MongoDB中要用IP地址不要使用机器名或localhost,不然会出现链接不数据库的。
The Linux Out of Memory OOM Killer:
情况一:
Feb 13 04:33:23 hostm1 kernel: [279318.262555] mongod invoked oom-killer: gfp_mask=0x1201d2, order=0, oomkilladj=0
这是因为内存溢出导致mongodb进程被刹死
情况二:
内在没有溢出,能过db..serverStatus()或mongostat查看内存virtualbytes - mappedbytes的界限
情况三:
ulimit的限制
t:minor-latin; mso-fareast-font-family:宋体;mso-fareast-theme-font:minor-fareast;mso-hansi-font-family: Calibri;mso-hansi-theme-font:minor-latin'>中journal是支持回滚恢复。
journaling的时候,stop m ongod ,clone, and tehn restart
注意:在MongoDB中要用IP地址不要使用机器名或localhost,不然会出现链接不数据库的。
mongodb占用空间过大的原因,在官方的FAQ中,提到有如下几个方面:
1、空间的预分配:为避免形成过多的硬盘碎片,mongodb每次空间不足时都会申请生成一大块的硬盘空间,而且申请的量从64M、128M、256M那样的指数递增,直到2G为单个文件的最大体积。随着数据量的增加,你可以在其数据目录里看到这些整块生成容量不断递增的文件。
2、字段名所占用的空间:为了保持每个记录内的结构信息用于查询,mongodb需要把每个字段的key-value都以BSON的形式存储,如果value域相对于key域并不大,比如存放数值型的数据,则数据的overhead是最大的。一种减少空间占用的方法是把字段名尽量取短一些,这样占用空间就小了,但这就要求在易读性与空间占用上作为权衡了。我曾建议作者把字段名作个index,每个字段名用一个字节表示,这样就不用担心字段名取多长了。但作者的担忧也不无道理,这种索引方式需要每次查询得到结果后把索引值跟原值作一个替换,再发送到客户端,这个替换也是挺耗费时间的。现在的实现算是拿空间来换取时间吧。
3、删除记录不释放空间:这很容易理解,为避免记录删除后的数据的大规模挪动,原记录空间不删除,只标记“已删除”即可,以后还可以重复利用。
RepairDatabase命令:
数据库总会出现问题的,关于修复的方法如下:
运行db.repairDatabase()来整理记录,但这个过程会比较缓慢。
当MongoDB做的是副本集群时:可以直接把数据rm掉,然后再重新启动。
当在不是primariy server上运行时,会得到一个"clone failed for wkgbc with error: query failed wkgbc.system.namespaces"
解决方法:为了修复,需要restart server 不加--replSet选项并且要选用不同的端口
LINUX下找出哪个进程造成的IO等待很高的方法:
可以判断是不是IO问题造成的:
#/etc/init.d/syslog stop
#echo 1 > /proc/sys/vm/block_dump
#dmesg |egrep "READ|WRITE|dirtied"|egrep -o '([a-zA-Z*])'|sort|uniq -c|sort -rn|head
下面是从网上找的案例:
昨天我访问mongodb的python程序开始出错,经常抛出AssertionError异常,经查证只是master查询异常,slave正常,可判断为master的数据出了问题。
修复过程:
1、在master做db.repairDatabase(),不起作用; 这个时间很长
2、停止slave的同步;
3、对slave作mongodump,备份数据;
4、对master作mongostore,把备份数据恢复,使用–drop参数可以先把原表删除。
5、恢复slave的同步。
实例二:碎片整理-replSet架构
1、rs.freeze(60) 在60s内该机器无法成为primary
2、在primary机上进行rs.stepDown([120]) 让该机器成为从节点且在120s内不会成为primary
3、在primary上 ,可以将data的数据删掉 ,启动。数据会自动两步上去的。
版权声明
本文仅代表作者观点,不代表本站立场。
本文系作者授权发表,未经许可,不得转载。
本文地址:/shujuku/MongoDB/105064.html