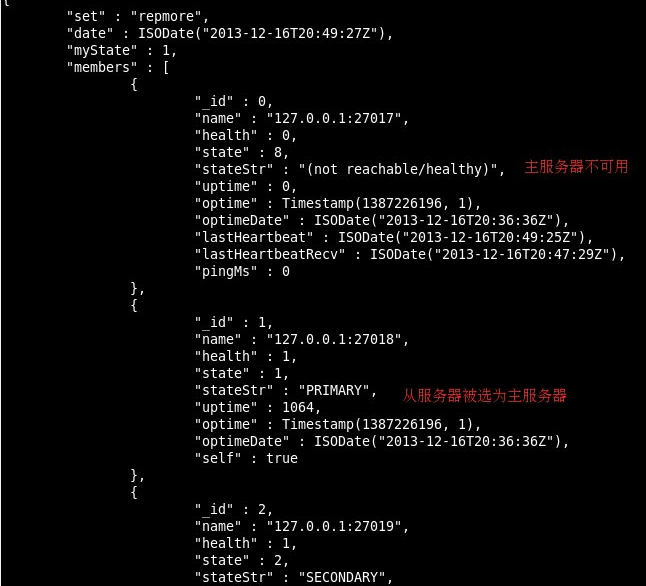
准备
在此之前,我们先在我们的数据库中插入10万条数据。数据的格式是这样的:
{
"name":"your name",
"age":22,
"gender":"male",
"grade":2
}
explain
explain方法是用来查看db.collecion.find()的一些查询信息的。例如:
db.collectionName.find().explain()
explain方法有个可选的参数verbose,是个字符串,他表示的是verbose的模式。一共分为3种模式:
queryPlanner:默认参数,详细说明查询优化器选择的计划并列出被拒绝的计划。例如:
db.students.find({grade:1}).explain()

executionStats:MongoDB运行查询优化器选择获胜的计划,执行计划,完成并返回成功,统计描述的胜利计划的执行。例如:
db.students.find({grade:1}).explain("executionStats")

allPlansExecution:MongoDB返回描述获奖计划的执行以及对其他候选人统计计划选择方案时捕获的统计。
我们的目的是要记录执行find方法的耗时时间,所以用executionStats模式就可以了。
返回的结果也是只关注executionStats就可以了,如下图:

- nReturned:表示该查询条件下返回的文档数量。
- executionTimeMills:表示执行时间,单位毫秒
- totalDocsExamined:表示该集合总共文档数。
其他的属性在这里就不多说了,记录耗时我们只取executionTimeMills.
Profiling
上面提到的方法好像是只适用find方法,对于一些聚合查询之类的查询方法就无法统计耗时时间了。这里再介绍一个profiling方法记录查询耗时时间。
开启 Profiling 功能
有两种方式可以控制 Profiling 的开关和级别,第一种是直接在启动参数里直接进行设置。
- 启动MongoDB时加上–profile=级别 即可。
- 也可以在客户端调用
db.setProfilingLevel(级别)命令来实时配置。可以通过db.getProfilingLevel()命令来获取当前的Profile级别。
例如:
db.setProfilingLevel(2) db.getProfilingLevel()

Profiling一共分为3个级别:
- 0 - 不开启。
- 1 - 记录慢命令 (默认为>100ms)
- 3 - 记录所有命令
Profile 记录在级别1时会记录慢命令,那么这个慢的定义是什么?上面我们说到其默认为100ms,当然有默认就有设置,其设置方法和级别一样有两种,一种是通过添 加–slowms启动参数配置。第二种是调用db.setProfilingLevel时加上第二个参数:
db.setProfilingLevel( level , slowms) db.setProfilingLevel( 1 , 10 );
查询 Profiling 记录
开启profiling功能后,系统会把相关命令详细信息记录到当前数据库的system.profile集合里。查询方法也是跟普通的集合查询一样。
db.system.profile.find()

其中,mills就是命令耗时记录。
由于我们设置的级别是2,所以所有命令都有记录,现在我们把他改为级别1,且只记录耗时20毫秒以上的记录:
db.setProfilingLevel( 1 , 20)

然后我们再执行一下聚合查询,查看下耗时时间:
db.students.aggregate( {$group:{_id:"$grade",avgAge:{$avg:"$age"}}} )

db.system.profile.find().pretty()

可以看出,我们的这聚合查询耗时70毫秒。
profile 部分字段解释
- op:操作类型
- ns:被查的集合
- commond:命令的内容
- docsExamined:扫描文档数
- nreturned:返回记录数
- millis:耗时时间,单位毫秒
- ts:命令执行时间
- responseLength:返回内容长度
下面介绍几个常用的查询命令:
列出执行时间长于某一限度(例如:20ms)的 Profile 记录.
db.system.profile.find({millis:{$gt:50}})

查看最新的 3条Profile 记录:
db.system.profile.find().sort({$natural:-1}).limit(3)

查看关于某个collection的相关慢查询操作:
db.system.profile.find({ns:'mydb.students'})
MongoDB 查询优化
docsExamined(扫描的记录数)远大于nreturned(返回结果的记录数)的话,那么我们就要考虑通过加索引来优化记录定位了。
responseLength 如果过大,那么说明我们返回的结果集太大了,这时请查看find函数的第二个参数是否只写上了你需要的属性名。(类似 于MySQL中不要总是select)
对于创建索引的建议是:如果很少读,那么尽量不要添加索引,因为索引越多,写操作会越慢。如果读量很大,那么创建索引还是比较划算的。
Profiler 的效率
Profiling 功能肯定是会影响效率的,但是不太严重,原因是他使用的是system.profile 来记录,而system.profile 是一个capped collection 这种collection 在操作上有一些限制和特点,但是效率更高。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对潘少俊衡的支持。
版权声明
本文仅代表作者观点,不代表本站立场。
本文系作者授权发表,未经许可,不得转载。
本文地址:/shujuku/MongoDB/104739.html